Classifying undergrad degrees with GPT-4 as our intern
At work, we very much want to understand whether people tend to apply to train to teach subjects for which their degrees are relevant.
But our data isn’t good enough.
This post is about training a neural network to classify degrees for us, and the part GPT-4 played in that process.
What CAH?
Ideally every teacher training application we held would have its degree mapped to a “Common Aggregation Hierarchy” (CAH) code. With a CAH code we can say with some confidence, for instance, that your degree in 20th Century Film Studies is relevant to your application to train to teach Drama. This is great because it helps us understand how and why teachers choose to teach the subjects they do.
We have about 20,000 free-text degree names lacking CAH codes. And there are 166 possible codes.
This is a classic “get a team of interns to do it” sort of task — it calls for skill and discrimination, but fundamentally it’s rote work.
The main problem with that approach is that we don’t have interns. Thankfully, GPT-4 is good at this! You can give it a list of the codes, then a list of unstructured degree text, and it will intelligently assign codes.
So one way to achieve degree coding is to loop through all 20,000 degrees and pack them off to GPT-4 over the OpenAI API.
And GPT-4 is good enough! How do we know? Because the results look reasonable, and the work simply cannot be done perfectly: nobody can sort degrees into 166 arbitrary categories precisely as the makers of the CAH would have intended.
In some ways it’s better than the interns. For instance, it can hold all 166 categories in its 8k context window - more than I could manage.
But it’s not perfect. Classifying a tranche of 200 degrees using GPT-4 takes about 3 minutes and costs roughly 25 cents. Multiply that by 100 (we have ~20,000 degrees to classify) and it’s 5 hours and costs $25.
One hour and $6.72 later
That cost is not awful, but 5 hours is quite a long time, and that’s the best case scenario — the OpenAI API falls over from time to time too so the process needs babysitting.
We can work with less, though. Having spent an hour and a small amount of money getting results for just 4,000 of our unlabelled degrees, we can put that data to use training a neural network. That’s interesting to do because
- it will be fast and free to run and we will be able to develop it as we learn more. GPT-4 is a black box
- if we can implement something that works for this dataset we can do look at using neural networks on other unstructured or incomplete data — of which we have a lot — some of which will have personally identifiable information in and is therefore unsuitable for sending to OpenAI
- we could run it next to the data in BigQuery where our analytics platform lives, which means we could potentially automate this kind of inference in future
Lumpy data
Before adding the GPT-4 data, this is what our data looks like, shown as a distribution of CAH codes. This core data is cobbled together from the official HECoS to CAH mapping (those 1,092 records, which I’m calling the CAH data) and some 2,000-odd rows of 2018 data from the Office for Students manually (I think!) mapping free text degrees to CAH codes, which we call the ILR data.
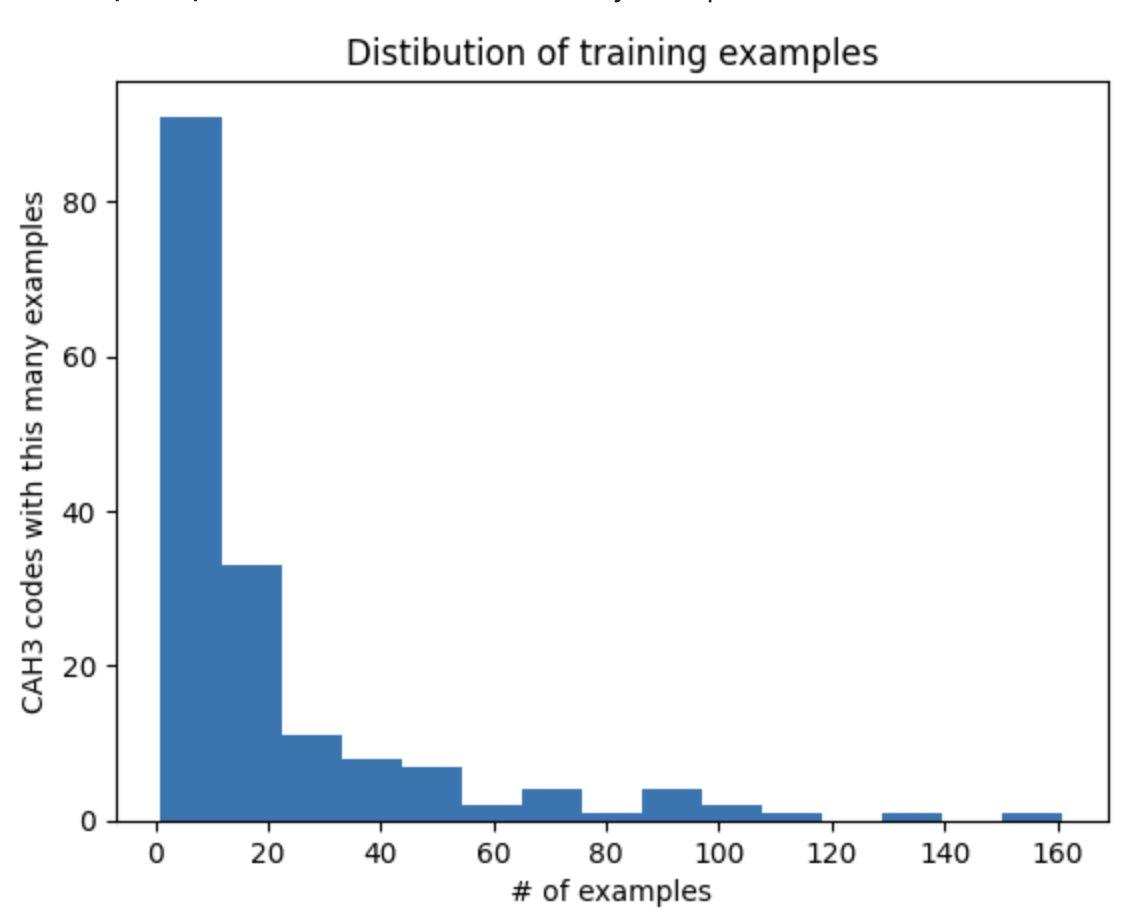
You can see that the overwhelming majority of CAH codes have fewer than 10 examples, but it’s very lumpy. Some codes have over 150!
We can and do use sklearn’s
compute_class_weight
feature to balance our training data to privilege underrepresented
classes, but its powers are limited when the absolute numbers are small.
More data should help!
Training a neural network
I trained a BertForSequenceClassification classifier from HuggingFace
Transformers on different quantities of data and evaluated the outcome in two ways:
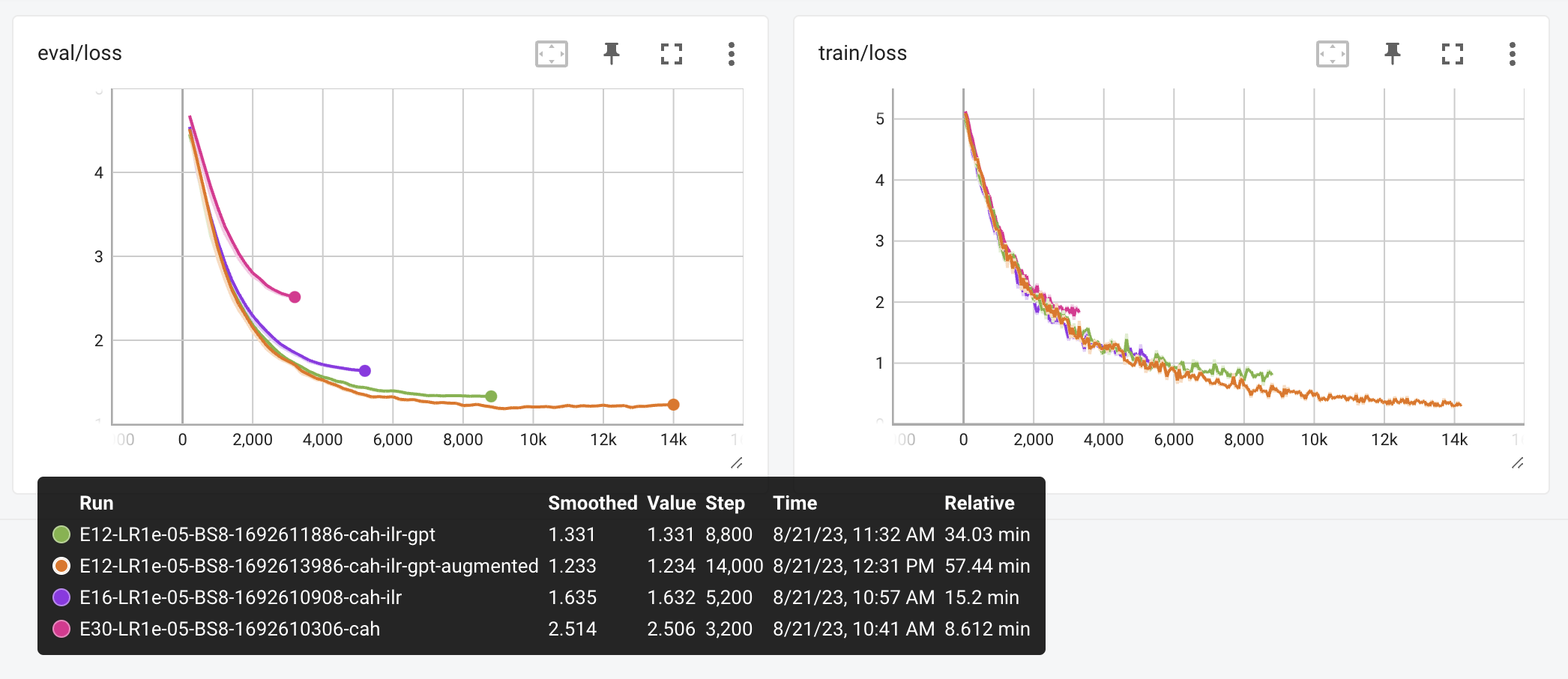
- the classic plot of training and evaluation loss — that is to say, how far the network’s predictions ended up from the “true” data in the training and test data, both of which are cut from the whole dataset
- by running the classifier against the 1,092 mappings in the original CAH list. That list is now a fraction of the data we have in the whole training set, and validating specifically against those “official” classes feels like a reasonable sanity check
Holding all other things constant, these were the results, with different quantities of training data.
Note that a CAH code, eg “07-01-01” has three parts, giving three levels of precision. CAH3 is the most specific and includes all three parts - something like “physics”. That’s the one we’re trying to assign here. CAH2 is two parts of the code, for example “physics and astronomy”. CAH1 is just the first part — e.g. “physical sciences”.
Given a significant amount of our relevance assessment relies on a matching CAH1 or CAH2 codes, 92% and 94% accurate matching is useful!
| Dataset | CAH3 % | CAH2 % | CAH1 % |
|---|---|---|---|
| 1. CAH | 49 | 65 | 70 |
| 2. CAH + ILR | 49 | 79 | 81 |
| 3. CAT + ILR + GPT | 63 | 87 | 89 |
| 4. CAH + ILR + GPT + SR | 78 | 92 | 94 |
*SR means I supplemented the training data with synonym replacement, creating new examples by replacing words in the original text with synonyms.
Classifications with the final, biggest dataset are significantly more accurate/plausible than those from the first. For example:
| Degree | Before | After |
|---|---|---|
| development in the Americas | teacher training | development studies |
| gas engineering | electrical engineering | chemical, process and energy engineering |
| vetinary pathology | chemistry | veterinary medicine and dentistry |
| rural planning | law | planning (urban, rural and regional) |
| Swedish language | Iberian studies | German and Scandinavian studies |
And here are the training and evaluation loss graphs for the various runs.
Conclusion
We’ve encoded some of GPT-4’s degree-categorisation skills into our own neural network which is good enough for our purposes, breaking our dependency on GPT-4 and opening up the possibility of doing this for more tasks in future.
We’re not ready to put this into production yet. If you’re interested you can find the code here.