What shall we forget next?
This is the text of a talk I gave at the GOV.UK developer day on 6 December 2023.

It’s an honour to be here. Thank you for having me.
Good news — I’m here to talk about documentation!
Yes, documentation, the least glamorous, lowest-tech part of software development.
I want to talk about it because documentation is changing, the way we write it and the way we read it. I want to talk about ADRs, and design histories of different kinds. And I’m afraid I want to talk about AI - but in quite a specific way.
And I want to do this because for me this is a way into to some fairly important questions for everyone in this room. Questions like: what is my work going to look like in 2 or 3 years time? Like: is my job going to exist?
And to spoil things a little bit, I believe the answer to the latter is yes, and.
And where we’re going in the next half hour is what comes after the and.
So this is how this talk will go.
First I’m going to rehearse the argument that technical documentation and software development are twins — inseperable halves of the same practice. You cannot have one without the other, although we talk about one a lot more than the other.
Secondly, I’m going to talk about the sort of softer sphere of documentation. This is where we’re going to pick up Design Histories and Architectural Decision Records (ADRs) and stuff like that.
And then the last part of the talk is going to be about how these two things are converging. And to flag the AI part, the thing that makes this possible are these miraculous documentation-generating machines like ChatGPT, which perhaps aren’t that good yet but the direction of travel, even in a world where the “AI” bit doesn’t get meaningfully more powerful in the next few years, is I think quite clear.

“Programs must be written for people to read, and only incidentally for machines to execute.” — preface to the first edition of Structure and Interpretation of Computer Programs, Harold Abelson & Gerald Jay Sussman with Julie Sussman, 1984.
I like this quote. I like it because it’s a bit provocative, like you could cut the whole second half off and it would merely be a bit less spicy, but it’s also obviously true. The reason why we have programming languages is to provide a human interface for the computer. And even if we were all hermits (which we aren’t), we’d need to read our own code, because time passes and we forget.
Maybe not written for people to read, but also having the quality of documentation, is running software, even without code. That’s a fixed process that’s being followed minutely, possibly thousands of times a second, and it’s observable, and all the information is there inside the system, so it should be understandable. There’s a model in there. Even systems we don’t understand like large neural networks, and in cases like that it’s more that we don’t know how to read yet, rather than that the information about what’s happening isn’t there.
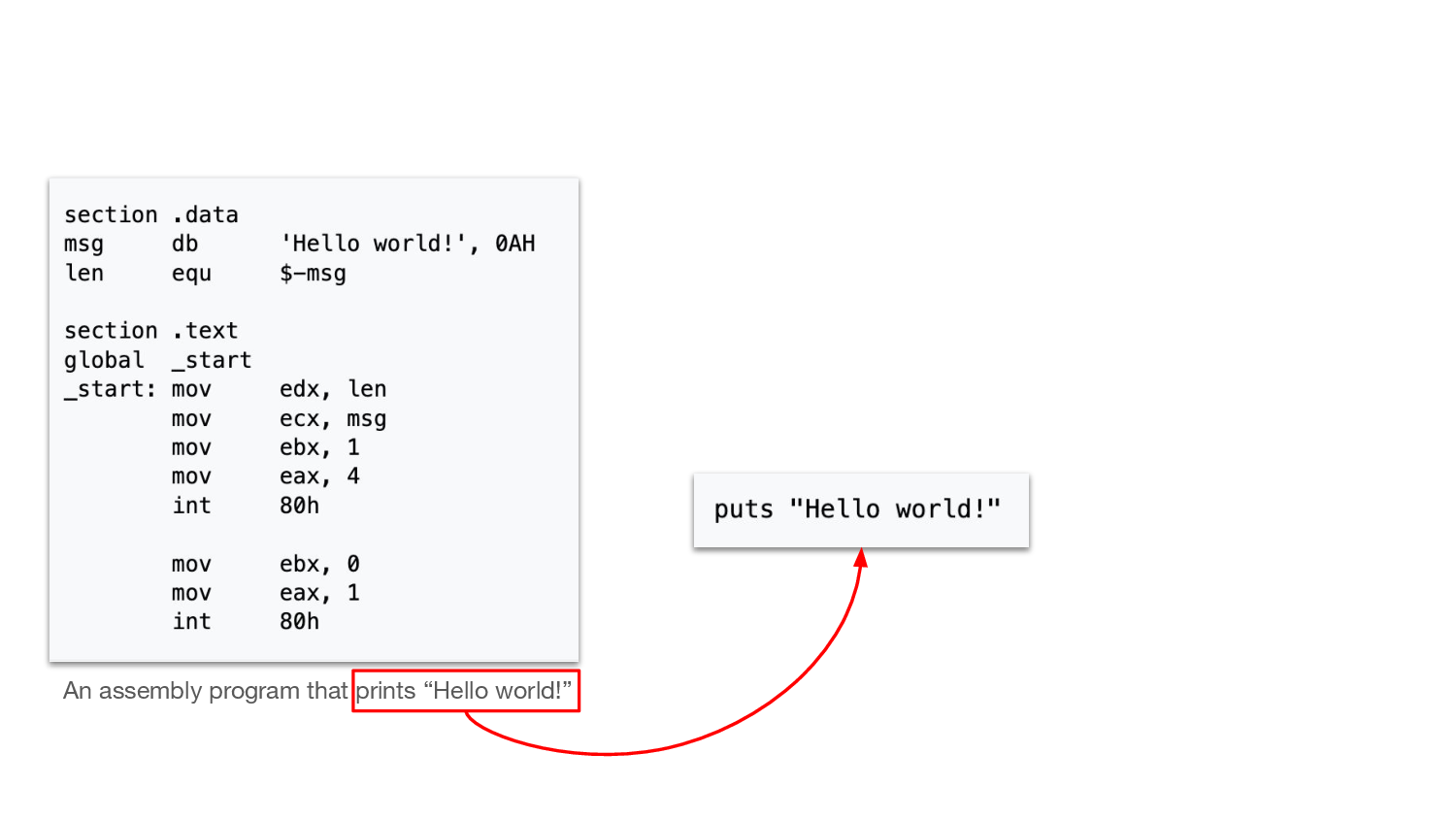
How does it document? Not in English, in spongy sentences. English isn’t executable because it’s not formally specified, so how could code possibly be written in English? But even so, it is true that the code does document. It does say the steps.
 And different languages make different decisions about what they care
about expressing. I mean here’s hello world in x86 assembly, and hello
world in C, and hello world in Ruby.
And different languages make different decisions about what they care
about expressing. I mean here’s hello world in x86 assembly, and hello
world in C, and hello world in Ruby.
 Let’s go further, here’s a low-code environment, which we can call, if
we’re feeling lively, a low-documentation environment. Less text! I
always feel like they kind of throw the baby out with the bathwater and
basically they’re saying less information, less documentation is better,
and of course the tradeoff is you exchange the text for this kind of
thing. But I think the key question is, is it expressive. And the thing
about traditional low-code environments, I gather, is that they tend to
be not expressive compared with text, which for logic (if you add a
couple of symbols) and storytelling is the most expressive material in
existence.
Let’s go further, here’s a low-code environment, which we can call, if
we’re feeling lively, a low-documentation environment. Less text! I
always feel like they kind of throw the baby out with the bathwater and
basically they’re saying less information, less documentation is better,
and of course the tradeoff is you exchange the text for this kind of
thing. But I think the key question is, is it expressive. And the thing
about traditional low-code environments, I gather, is that they tend to
be not expressive compared with text, which for logic (if you add a
couple of symbols) and storytelling is the most expressive material in
existence.
 But this is progress, we like this — the transition from assembly to
Ruby.
But this is progress, we like this — the transition from assembly to
Ruby.
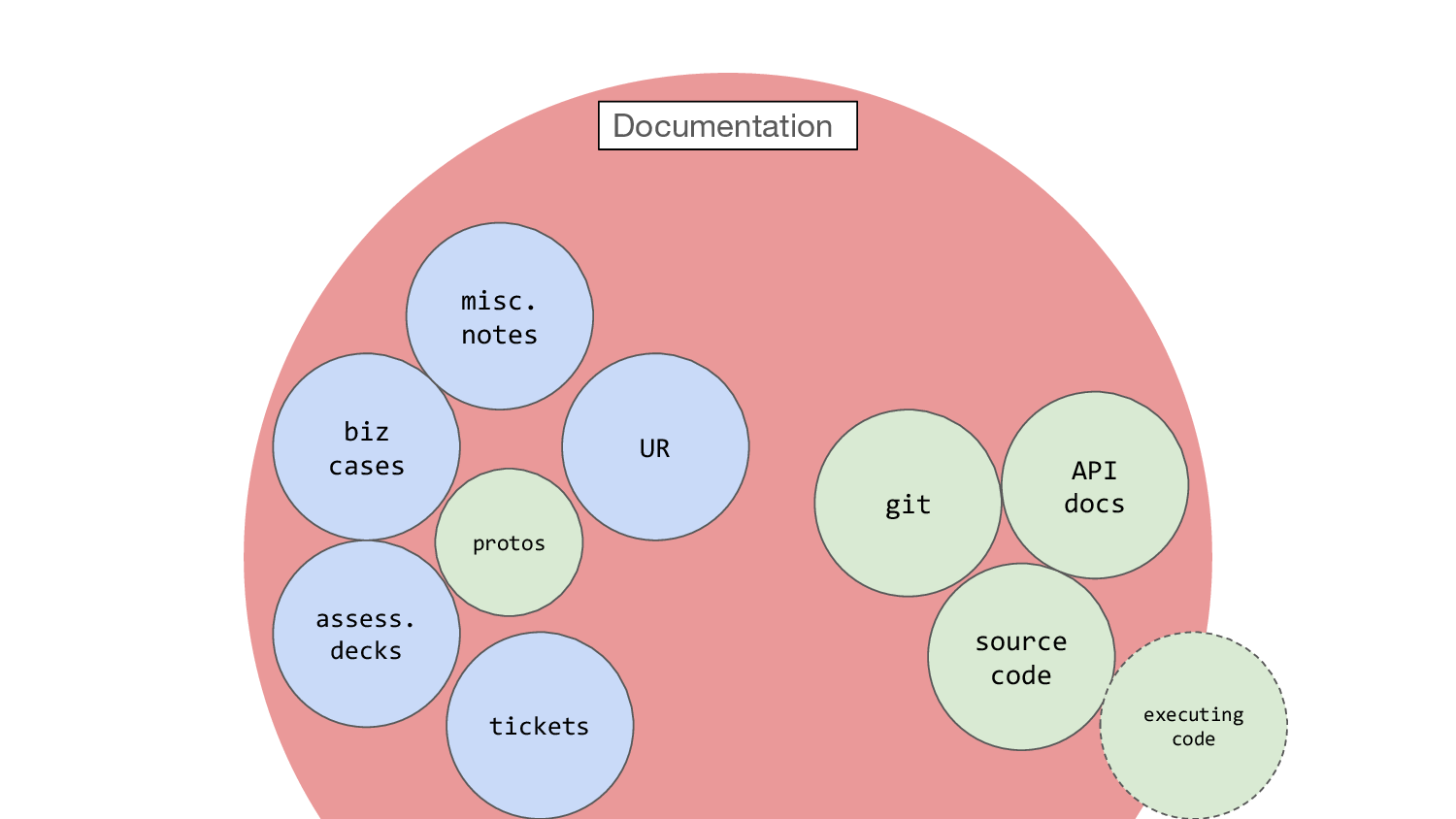
So I’m going to start a picture here, and be slightly controversial and say I think the venn diagram between source code and documentation actually kinda looks like this.
And the vast majority of this is words. With a few numbers, definitely, and an occasional picture. And this is identical with “work products”.
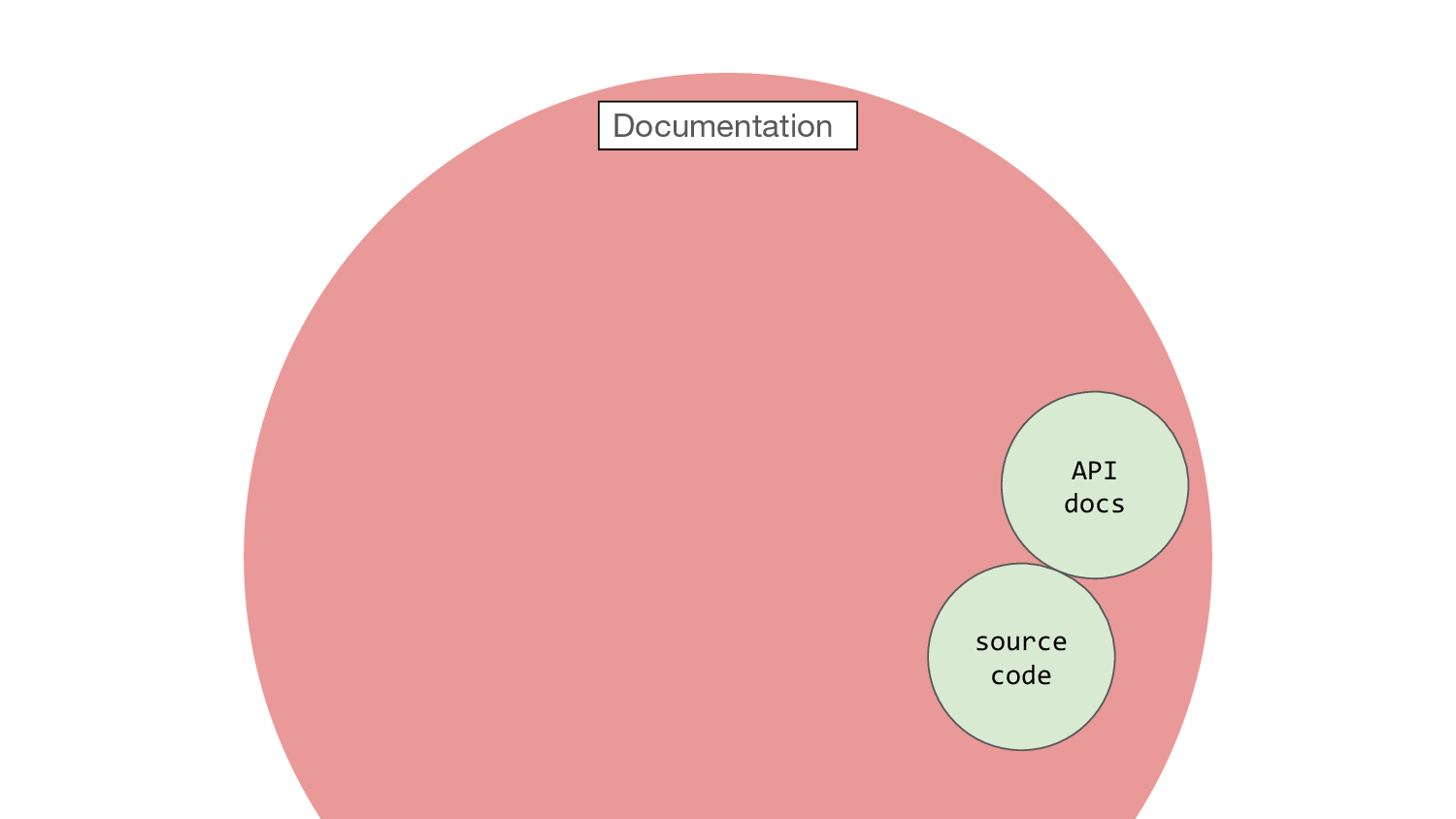
So just to build up this picture a bit, we have the source code and then just beyond here we have say API documentation, which can itself be executable thanks to OpenAPI. At DfE we have services where the API docs are generated from API specs, and the automated tests convert those OpenAPI specs to JSON schemas and use them to assert on the test inputs and outputs to the API. So the documentation is fully enmeshed in the code, that is, we have executable documentation.
This makes me very happy.
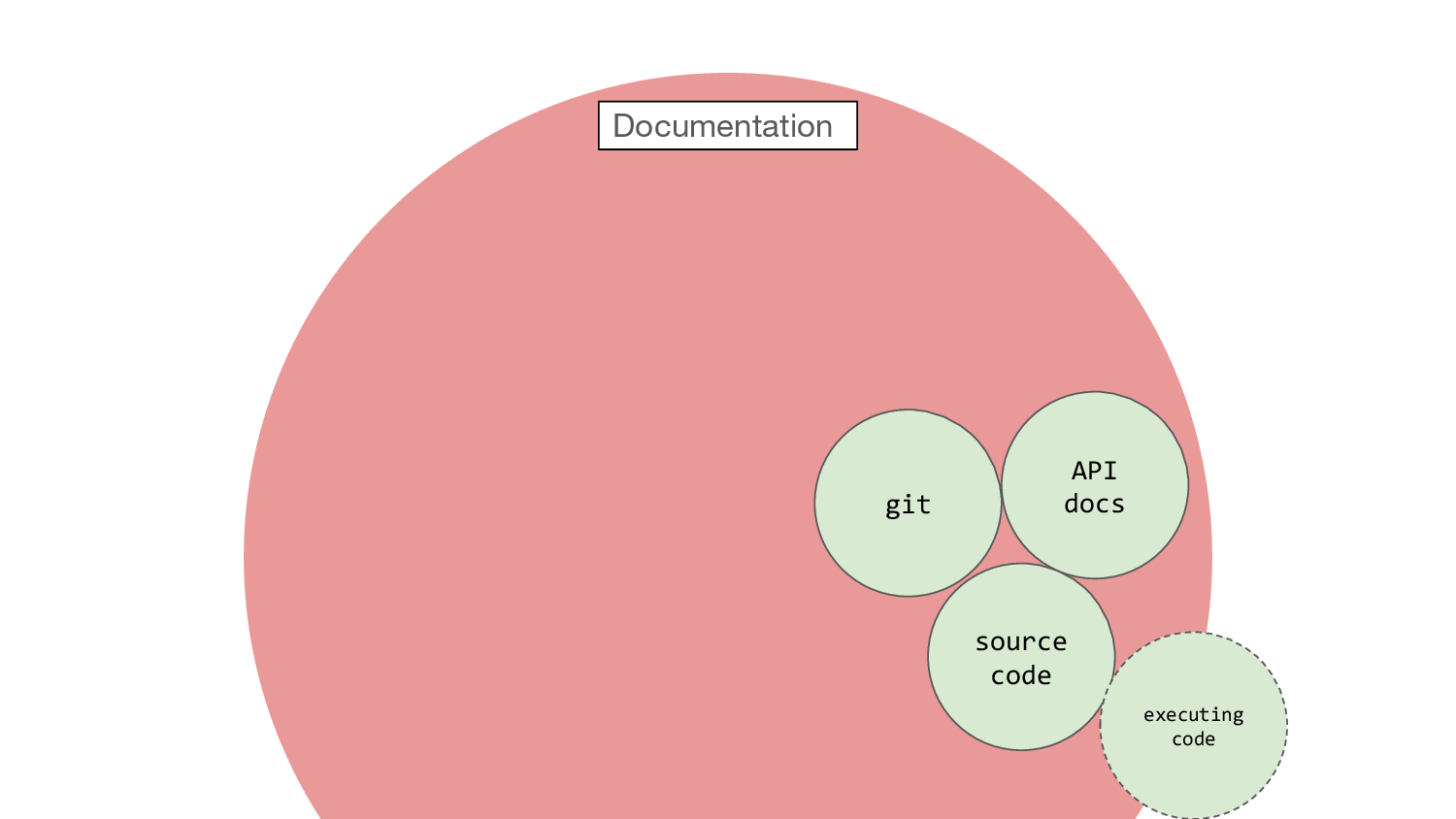 Let’s put another bit in here: git. I adore git. Little flakes of
documentation pinned to pieces of code like information canapés. Not
quite executable, but then you’re only ever a
Let’s put another bit in here: git. I adore git. Little flakes of
documentation pinned to pieces of code like information canapés. Not
quite executable, but then you’re only ever a git checkout away from
the exact state of the code at that time, which is executable. How
wonderful. If your team is writing good commit messages, of course…
which is, unfortunately, optional.
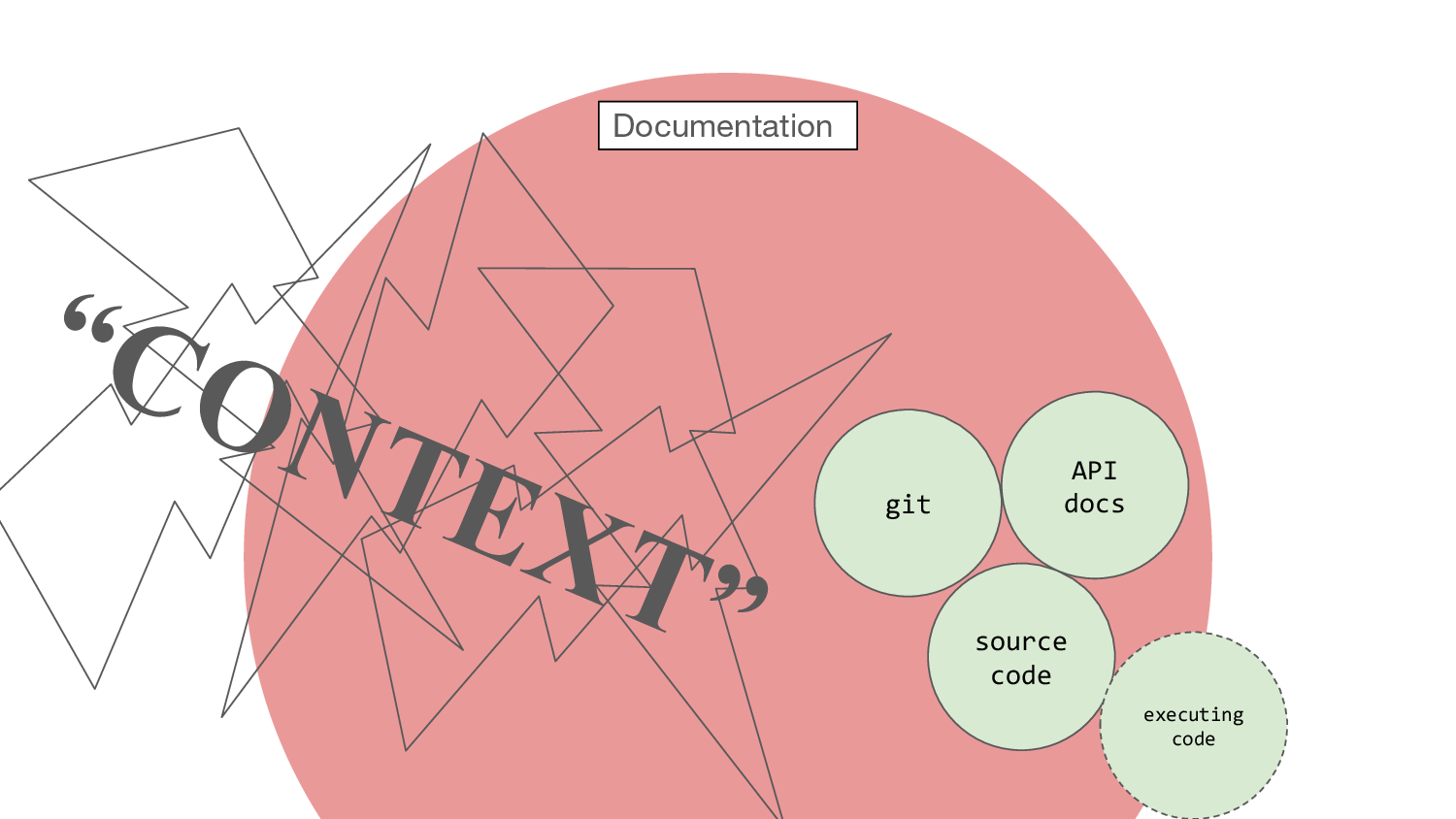 Let’s go and stand over here on the left. Outside the software.
All this stuff is executing, ie does something. Why is it here? Why does
it do what it does? Why doesn’t it do something else? Because the reason
why it does what it does doesn’t come from inside it. Code doesn’t, of
itself, yearn to come into being. But people yearn to make things and
sometimes they’re told that they have to make things.
Let’s go and stand over here on the left. Outside the software.
All this stuff is executing, ie does something. Why is it here? Why does
it do what it does? Why doesn’t it do something else? Because the reason
why it does what it does doesn’t come from inside it. Code doesn’t, of
itself, yearn to come into being. But people yearn to make things and
sometimes they’re told that they have to make things.
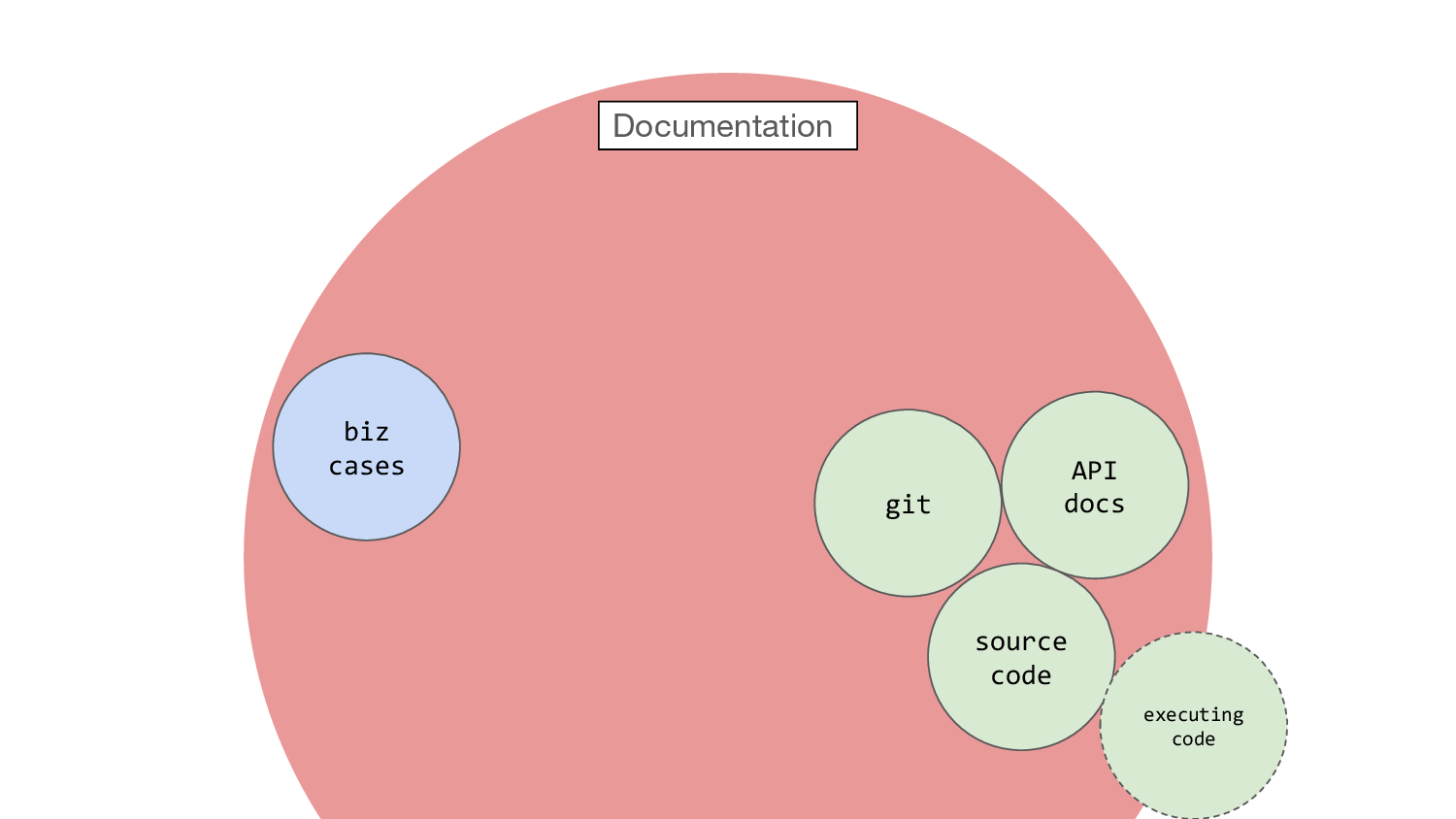 I don’t know how much anyone in this room has had to do with this kind
of thing, but in the past couple of years I’ve had to deal with business
cases, which are documents asking for money and people to achieve an
outcome. And to write a business case you have to fill in some big text
boxes which describe what your work is for and why you want to do it.
And not novel, contentious or repercussive and other curious stuff like
that. And then they give you the money and then you do it. Hopefully! So
that’s usually an early draft of why something is happening, and you may
find over the course of the next couple of years that you and your team
refer to it to try and remember what exactly it was you said you would
do, and what others expect of you.
I don’t know how much anyone in this room has had to do with this kind
of thing, but in the past couple of years I’ve had to deal with business
cases, which are documents asking for money and people to achieve an
outcome. And to write a business case you have to fill in some big text
boxes which describe what your work is for and why you want to do it.
And not novel, contentious or repercussive and other curious stuff like
that. And then they give you the money and then you do it. Hopefully! So
that’s usually an early draft of why something is happening, and you may
find over the course of the next couple of years that you and your team
refer to it to try and remember what exactly it was you said you would
do, and what others expect of you.
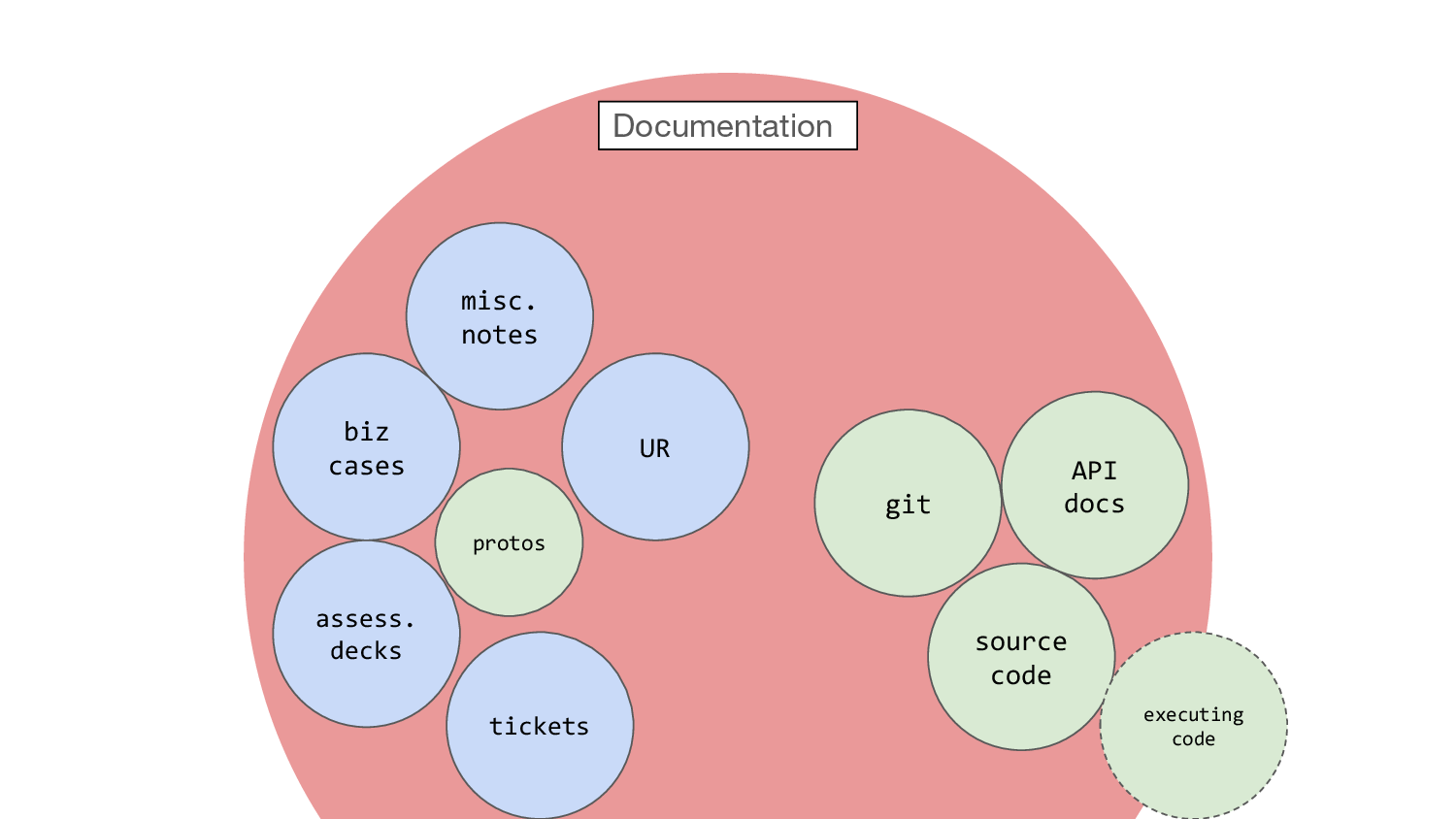 When you’re writing a business case you probably have some research
documents and some hypotheses written down, and of course you’ve got all
the temporary stuff that goes with discovery, notes and maybe screen
recordings and stuff, and maybe you’ve even got some prototype code, a
little remnant of executable documentation reflecting what you thought
at moment in time. And in due course you’ll augment this with assessment
decks and all their ephemera as you move from discovery to alpha to
beta.
When you’re writing a business case you probably have some research
documents and some hypotheses written down, and of course you’ve got all
the temporary stuff that goes with discovery, notes and maybe screen
recordings and stuff, and maybe you’ve even got some prototype code, a
little remnant of executable documentation reflecting what you thought
at moment in time. And in due course you’ll augment this with assessment
decks and all their ephemera as you move from discovery to alpha to
beta.
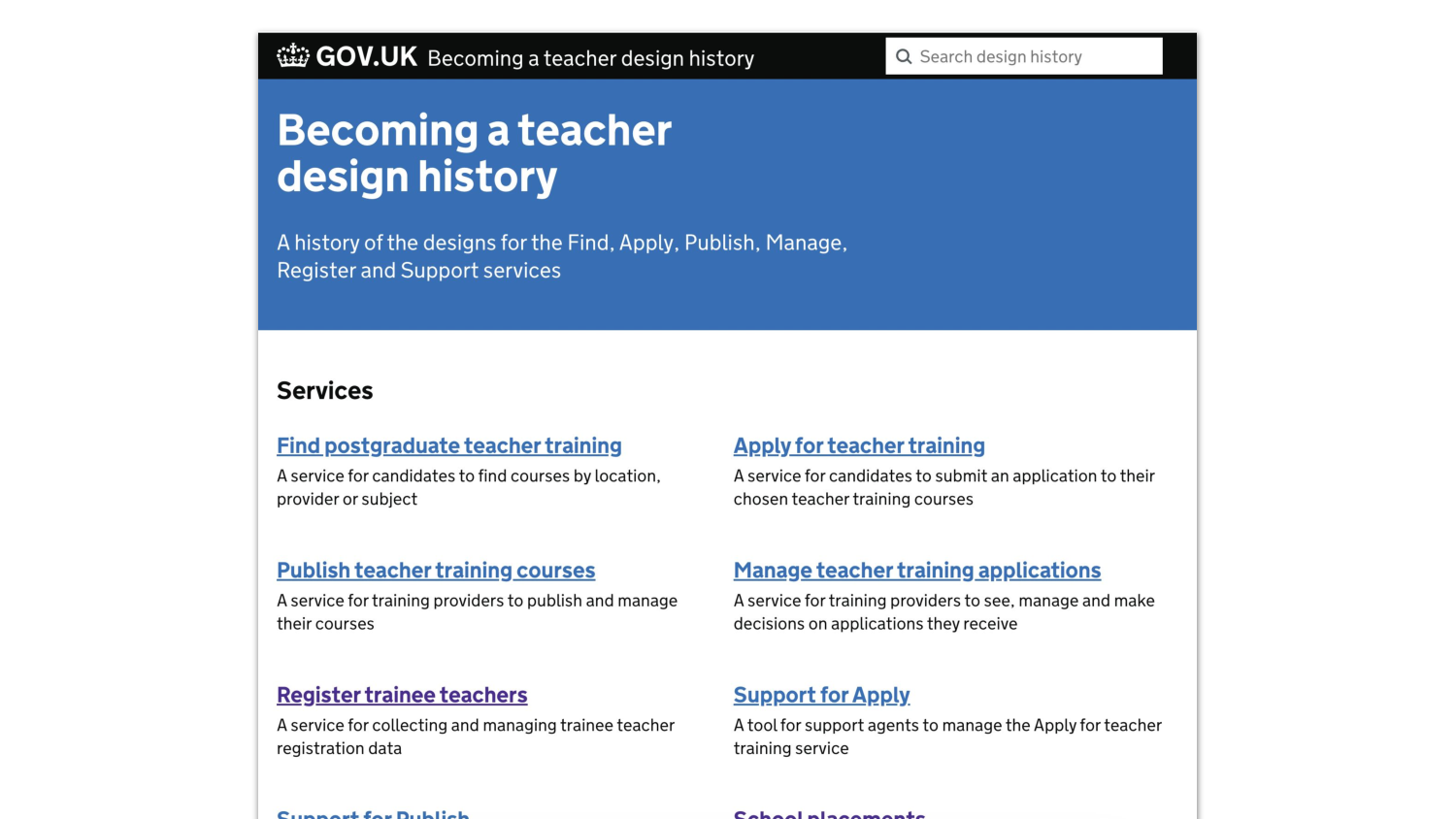 And let’s say your business case is successful, and you go on writing
down your decisions because you feel like it might be a good idea. You
might end up with something like this, which we call a Design History.
You can see the different services it deals with here.
And let’s say your business case is successful, and you go on writing
down your decisions because you feel like it might be a good idea. You
might end up with something like this, which we call a Design History.
You can see the different services it deals with here.
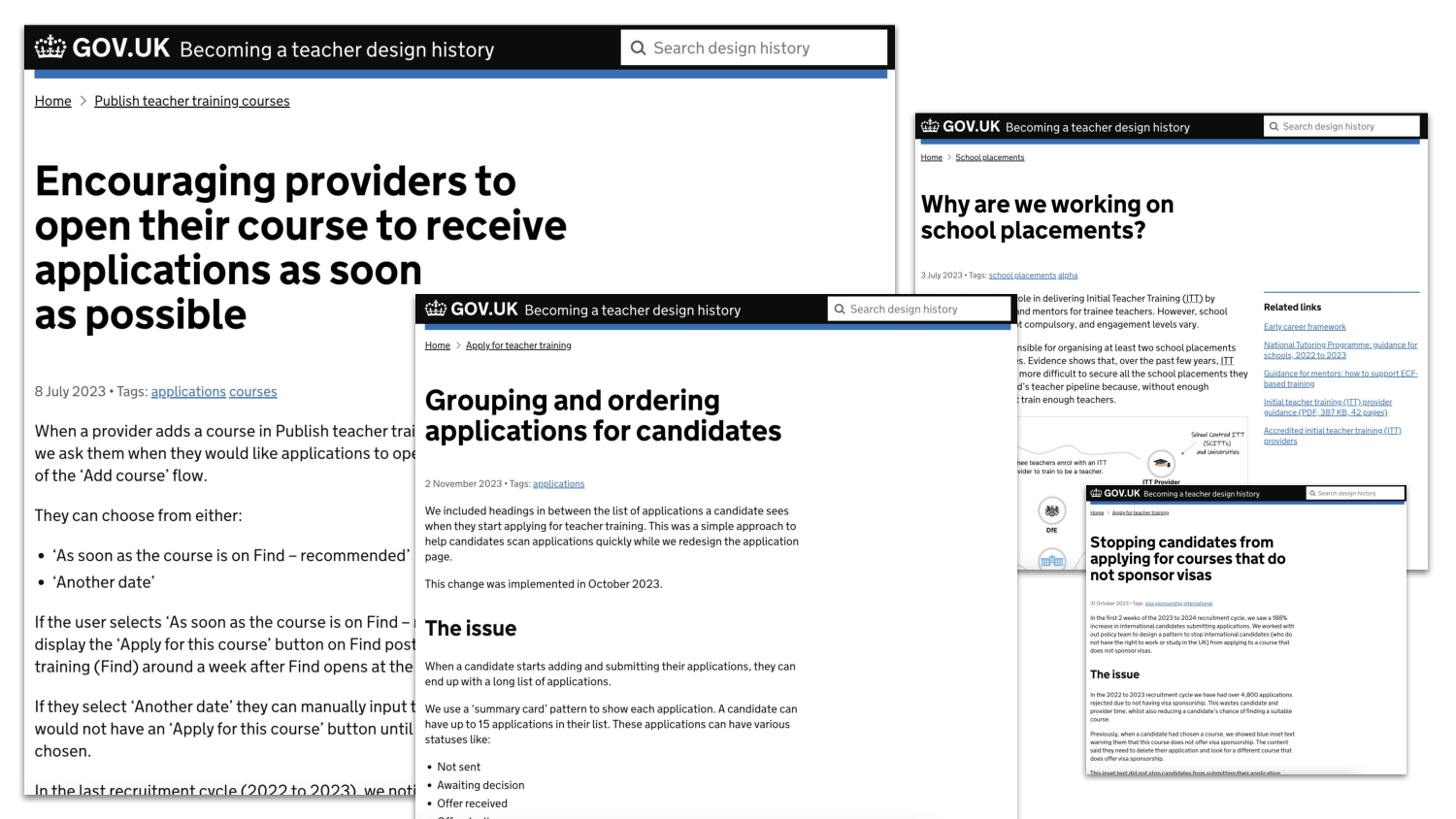
Someone called Paul Hayes started this in our bit of DfE, and he’s gone, but it lives and lives, and every time we have a new service we add more sections and pages to the design history. This documents design decisions in the services. It’s not just interaction designers and URs who do this; we also have “policy people”—which is an outdated, pejorative label, but it’s all we’ve got for the time being—writing Policy design histories. Decision artefacts. Like architectural decision records, but for the context.
This is really cool. Is anyone doing it? If you do do it, an interesting thing happens, which actually seems quite obvious in hindsight, which is that you’ll notice that people will start mistaking completing a design history entry for delivering finished work.
In fact there is a real risk when you’ve got one of these that designers run way ahead “delivering” a bunch of stuff that has never been tested in the fires of production. They write these things and then they shed the context and then they move on to the next thing.
I reflect on the time when I was in a team where this happened, the fact that these things were shippable annoyed me, because it wasn’t code, because it got us out of phase and slowed us down. But I wonder if that tension, and that feeling of decision that comes with them, is also maybe an opportunity to think a bit harder about the role this activity might play in the future, the scraping up, writing and forgetting, out here in the big world, and what bearing that might have on how and what we build.
Anyway that brings us late to the title of this talk
 Which is WHAT SHALL WE FORGET NEXT?
Which is WHAT SHALL WE FORGET NEXT?

There’s the stuff you forget by accident, and there’s the stuff you forget because you don’t need to remember any more, and we’re talking about the second sort here. This is what we aim for in software design - we want maximum benefit for smallest cognitive load, forget everything but your intention, that’s the dream API.
So maybe a way to think about these design histories is that they enable us to forget contextual stuff in the same way that in software an abstraction helps us forget procedural stuff. These have something in common, which is the drawing of a boundary and a naming—a decision.
But clearly they are not the same thing.
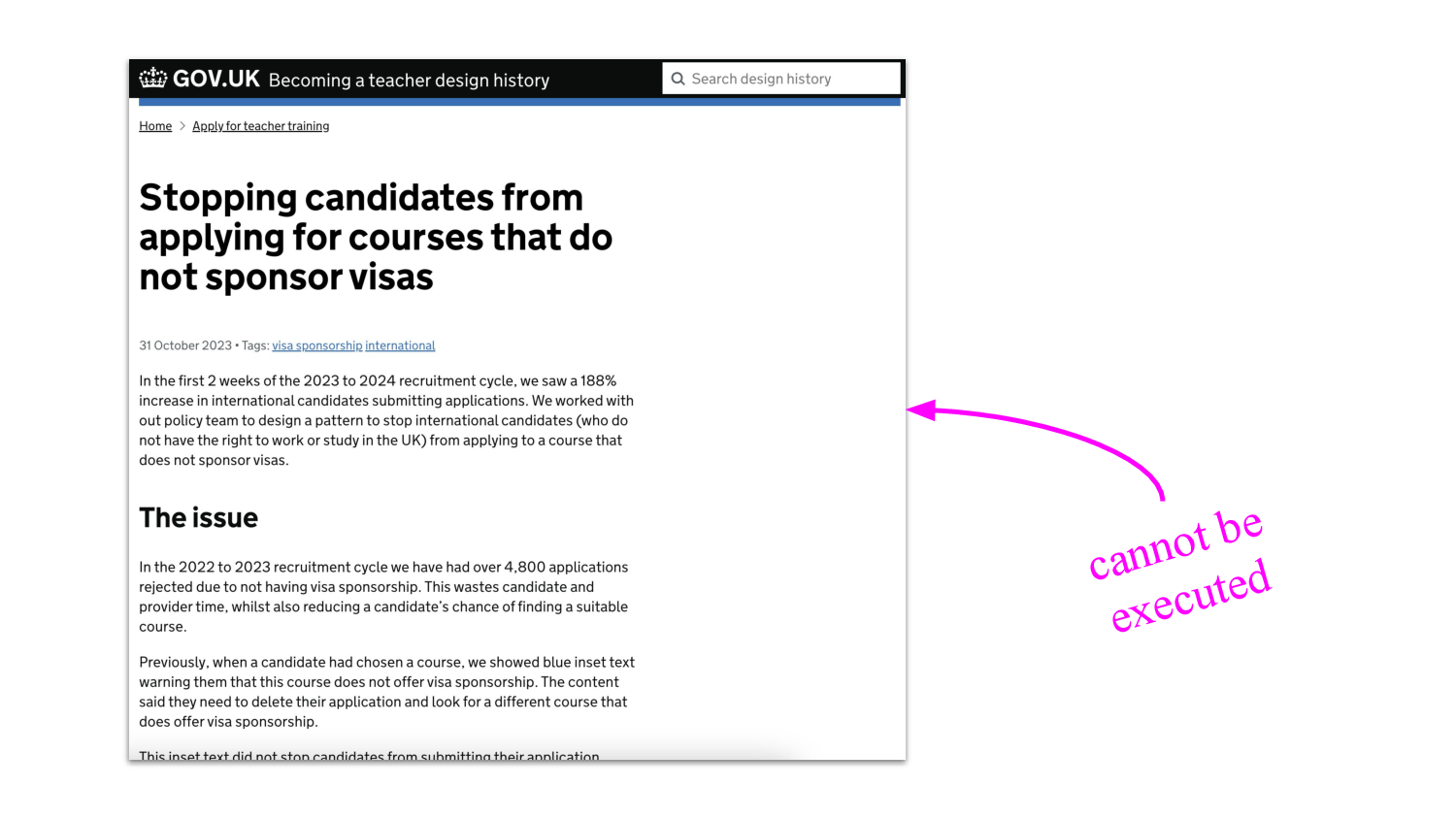 For a start, this thing is not executable! Shortly we’ll ask what would
it do if it could be executed. But for now it can’t be executed so it’s
optional — I mean if your code starts talking about concepts that
don’t exist, or concepts that used to exist and don’t anymore, then your
program will crash. In fact it’s meant to go out of date, that’s where
its value is. A kind of breadcrumb trail that tells us how we got here.
For a start, this thing is not executable! Shortly we’ll ask what would
it do if it could be executed. But for now it can’t be executed so it’s
optional — I mean if your code starts talking about concepts that
don’t exist, or concepts that used to exist and don’t anymore, then your
program will crash. In fact it’s meant to go out of date, that’s where
its value is. A kind of breadcrumb trail that tells us how we got here.
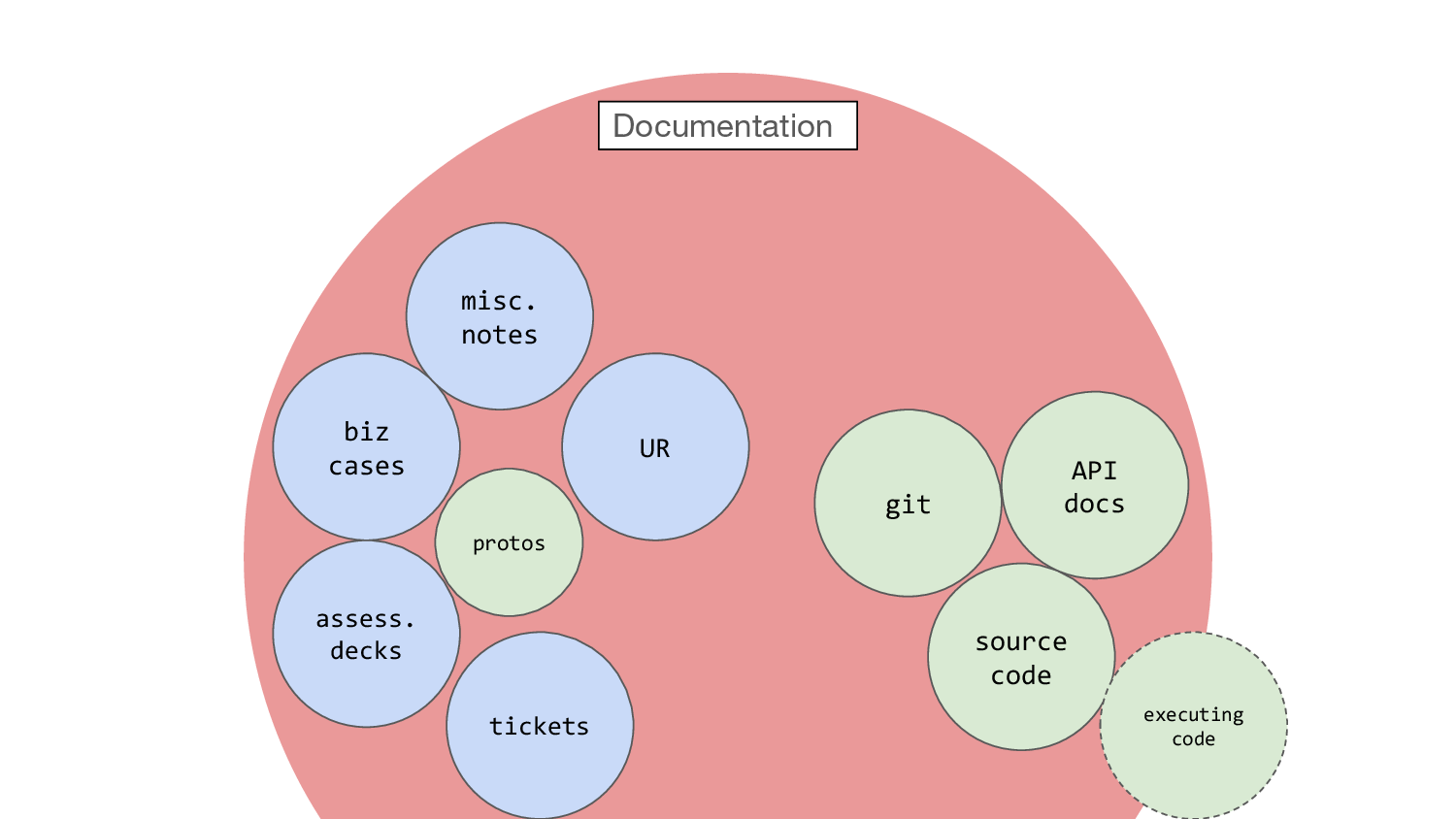 So let’s add some last bits to this diagram. Where does all this writing
come from?
So let’s add some last bits to this diagram. Where does all this writing
come from?
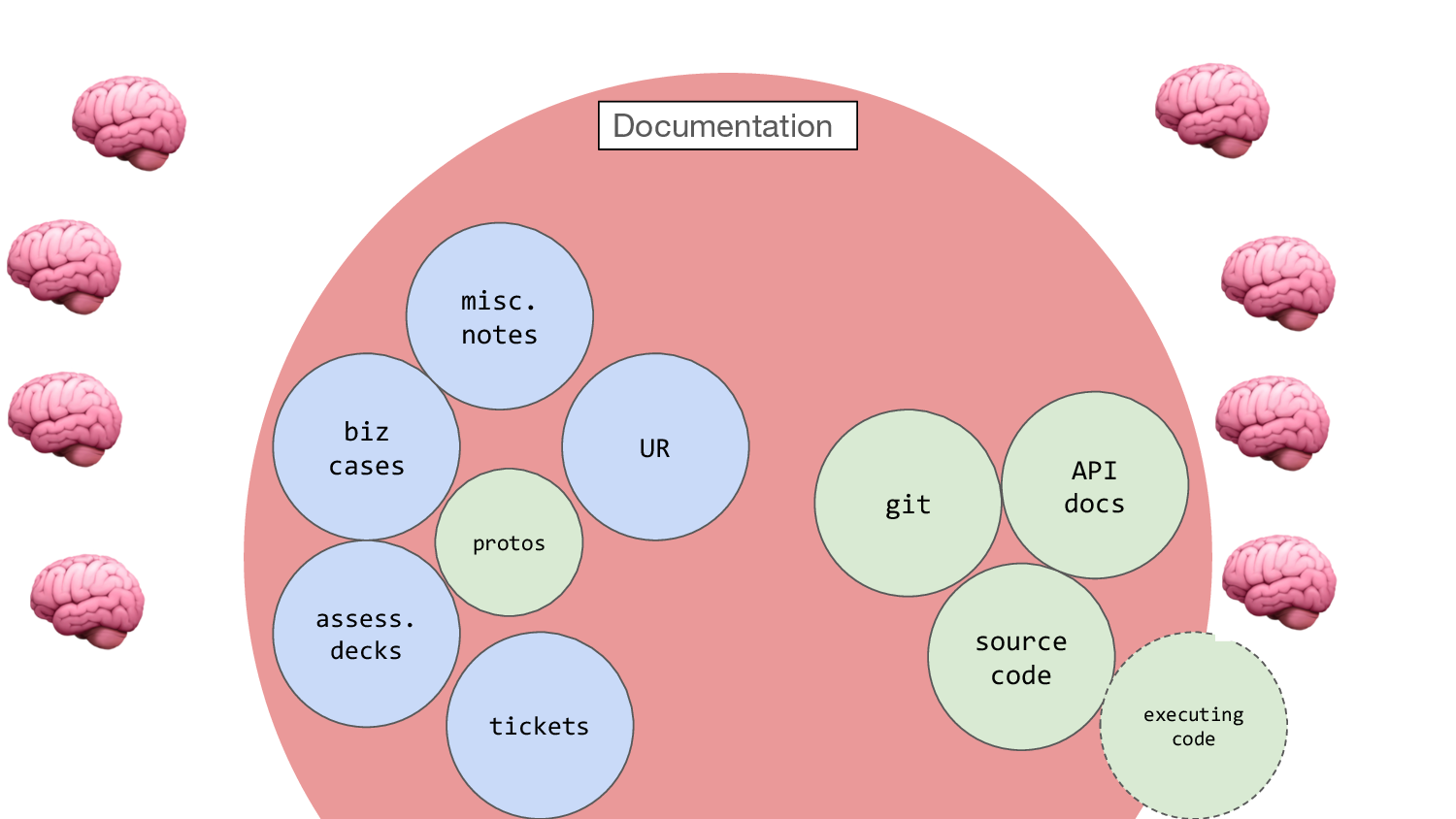
Let’s say our minds. There we are! A team. Some of the things we know we don’t write down, and some of the things that are written down, we don’t know. Etc.
So, all this is what we’ve written down, and it belongs to the team. In fact this is what the team “produces”: writing. And in the team there are these little silos of minds that know stuff. And these minds are the only things that can add to this.
I mean this is a monstrously abstract way of looking at work, of course.
So to do some work, one of these wakes up in the morning…
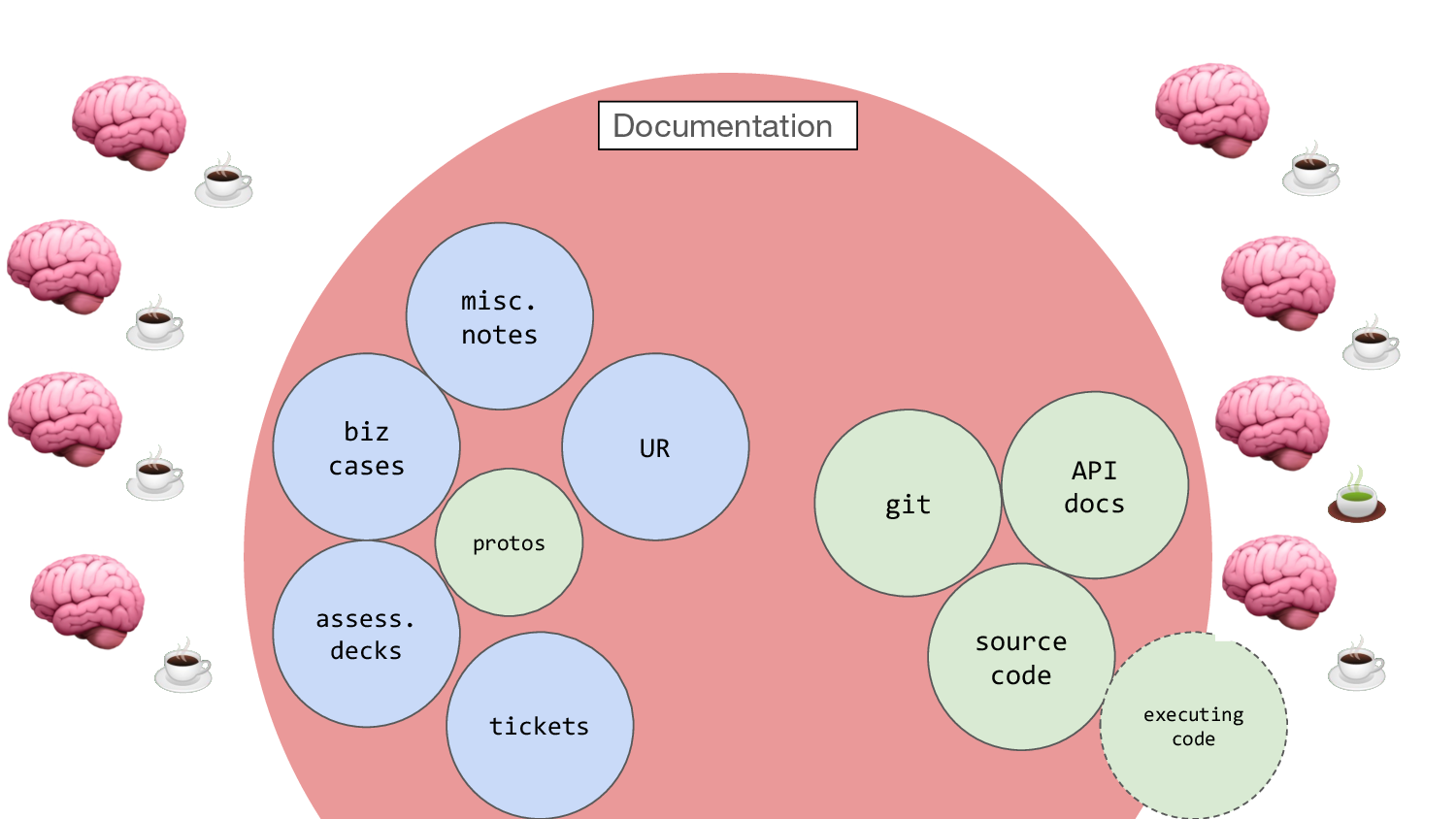 …and they have a coffee and they begin adding to this or that, trying
to understand it & shape the system. And they load in a little bit of
context, a little bit of this and a little bit of that.
…and they have a coffee and they begin adding to this or that, trying
to understand it & shape the system. And they load in a little bit of
context, a little bit of this and a little bit of that.
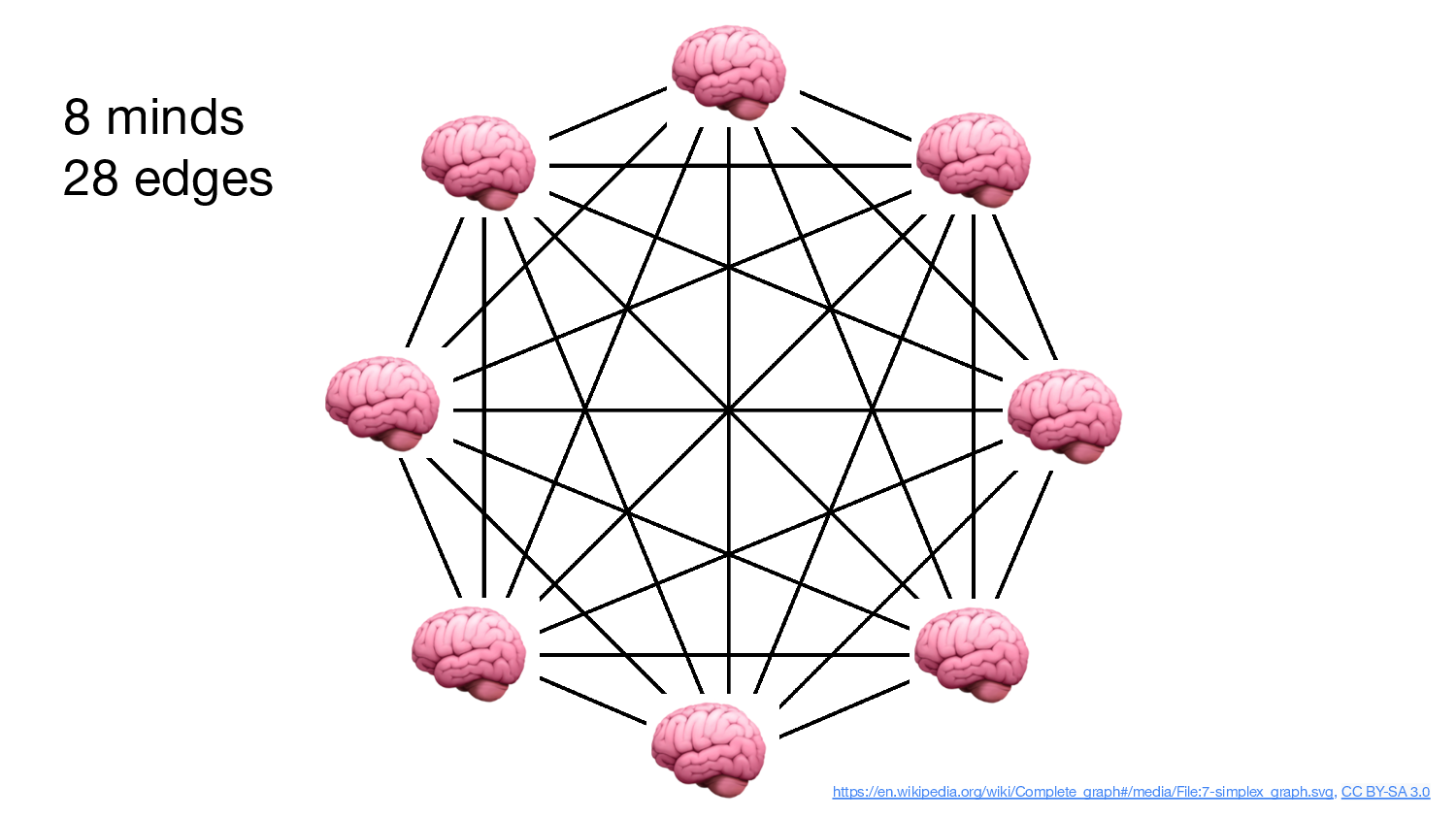
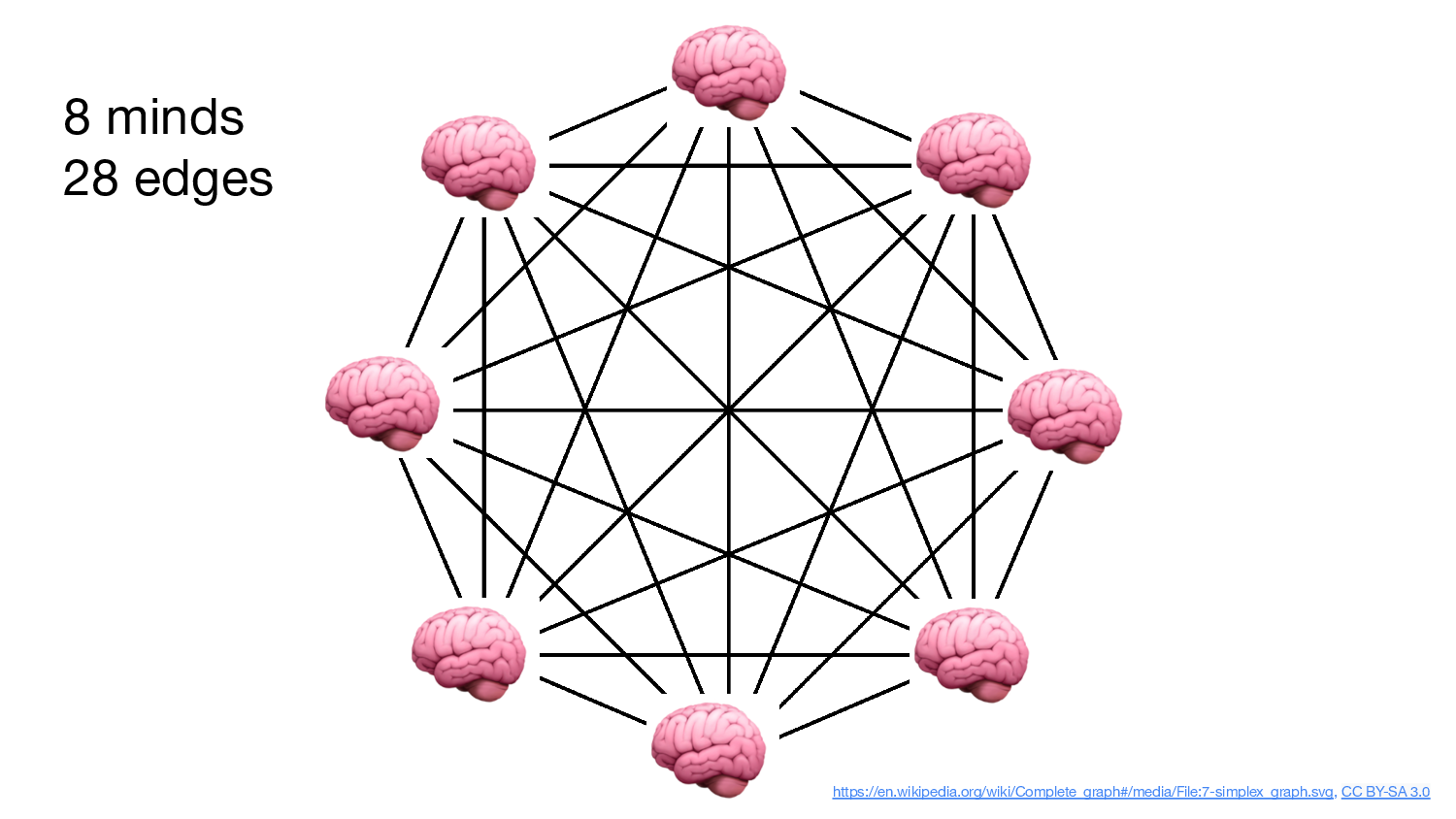 And look at the number of connections between these people. 8 people —
28 distinct connections!
And look at the number of connections between these people. 8 people —
28 distinct connections!
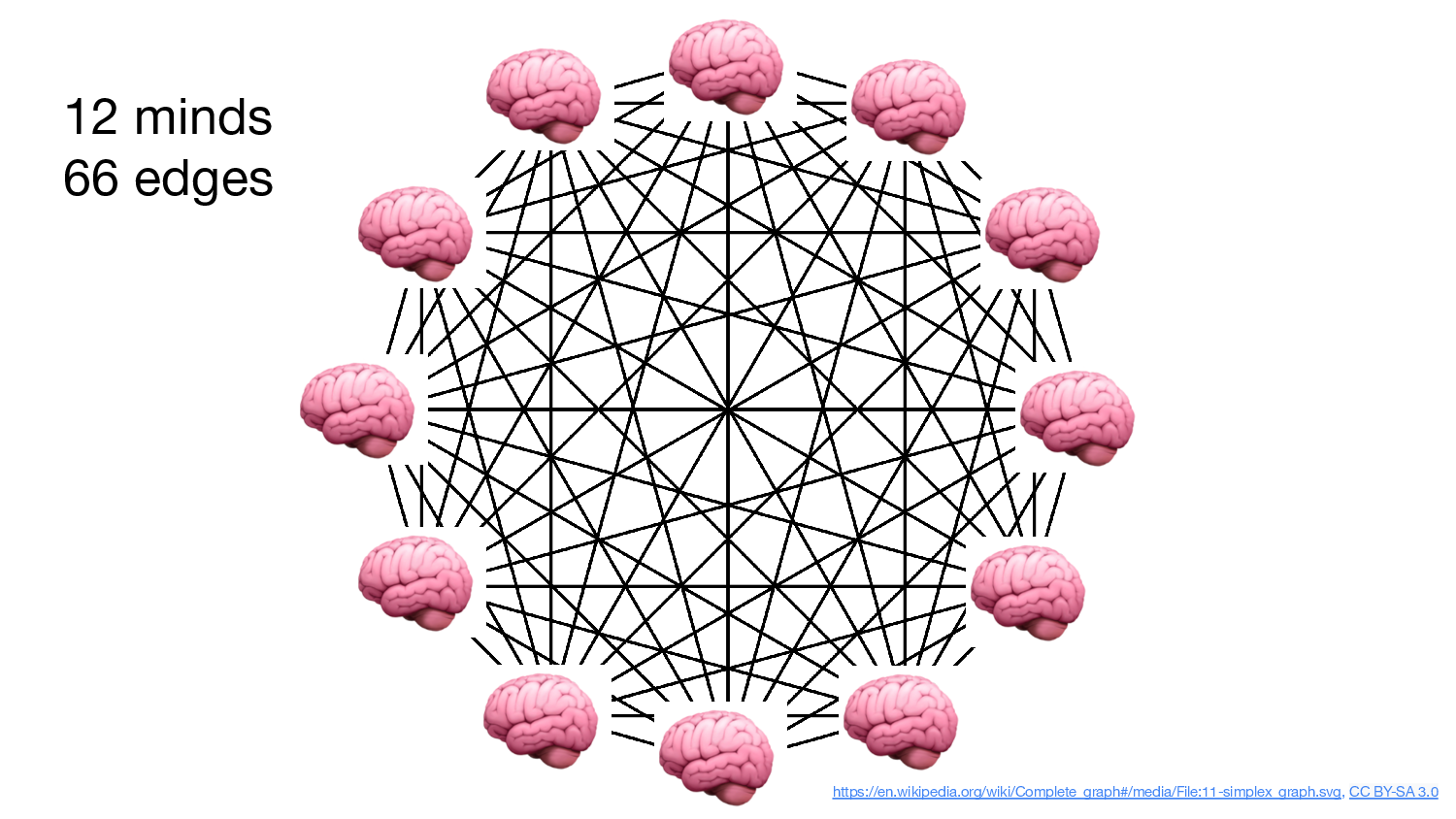 And it’s a cliché to observe this, but when you go from 8 people to 12
people and you more than double the connections. So much of what passes
over these channels is information, facts, knowledge. Just arriving at
consensus on what we know is exhausting. And when the information gets
there, good god, we put things in our “working memory”, which in
computers we call RAM and is populated at the snap of a billion
transistors, but in people is often called “context” as in “context
switch”, and it takes a relatively long time to populate.
And it’s a cliché to observe this, but when you go from 8 people to 12
people and you more than double the connections. So much of what passes
over these channels is information, facts, knowledge. Just arriving at
consensus on what we know is exhausting. And when the information gets
there, good god, we put things in our “working memory”, which in
computers we call RAM and is populated at the snap of a billion
transistors, but in people is often called “context” as in “context
switch”, and it takes a relatively long time to populate.
 I think we’ve all been here, for example. This black whirlpool. That’s
what it is to laboriously gather up the thread of your work… and then
lose it.
I think we’ve all been here, for example. This black whirlpool. That’s
what it is to laboriously gather up the thread of your work… and then
lose it.
And there’s so much of it. And actually I think in reality the scale is more like this, where the space where we’re working really kind of dwarfs the documentation, and so much of it is in-mind and based on memories, yesterday’s RAM. Because our minds, it’s proven, are quite bad at storage. We lack disks and filesystems. We unconsciously shape our memories around other bits of ourselves. We can’t really remember anything. And I’m not saying text is free of this kind of twisting, but it’s certainly a lot better, and executable code is even better, because it can have errors, and errors go bang and we notice.
Cognitively this is utterly overwhelming, especially if you consider how much time it takes to context switch, and I’m pretty sure it’s a common experience — it’s certainly been true for me — that if you’re in a role that spans more than one team or more than one domain or subdomain, it’s totally possible to get into a state where you’re basically always mid-context switch, and if you want to focus properly on anything you have to absolutely whip your mind, and it all just ends up feeling masochistic.

But we’re not going down that road today. I just want to observe that a team (or an individual!) that thinks about what it knows and takes the trouble to write it down is going to be a healthier, happier team than one which doesn’t. That team know that the way to shed cognitive load is to ignore, or to forget. And the act of deciding is specifically an act of forgetting.
Because we just have to allow some things to be true. Users do need a
service that allows them to Find teacher training courses.
SubmitTeacherTrainingAppliction will submit a teacher training
application. And puts is practically guaranteed to print a
newline-terminated string on standard out.
So where I want to go with this now, is that it’s a happy coincidence that we’re in the habit of creating design histories, we’re discovering this new kind of done-ness, and we also have a new way to work with things that are done, and by that I mean stuff like this:

I’m just going to leave this on loop here.
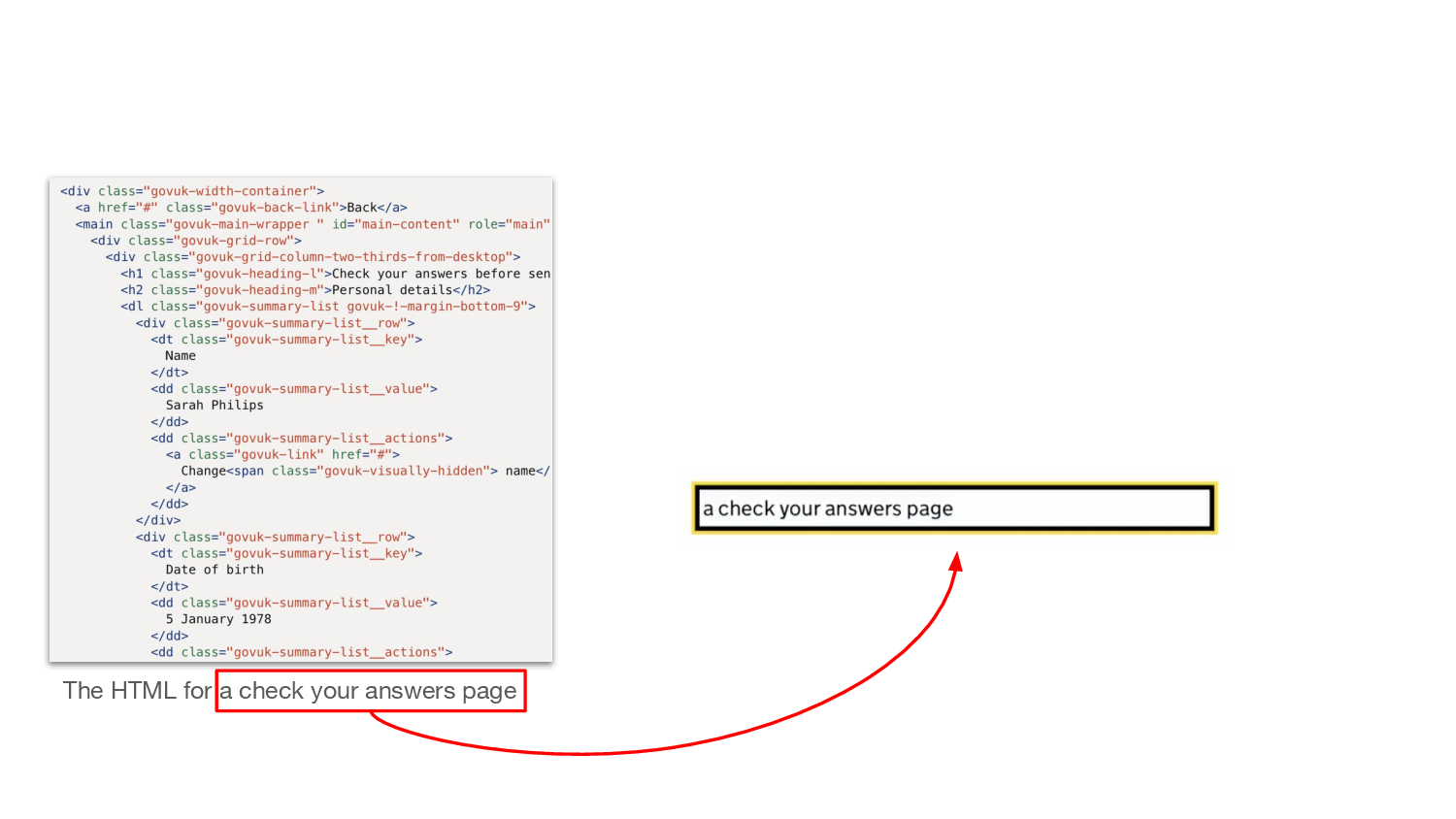
The link is to an LLM-powered tool which generates working HTML pages from a text description of components in the GOV.UK Design System.
Fred Brooks makes a useful distinction between essential and accidental complexity — the stuff you actually care about, as he puts it “those [parts] concerned with fashioning abstract conceptual structures of great complexity”, and the stuff you need to care about, computers and whatnot, to get anything done. And this — this HTML generation, is what it feels like to shed accidental complexity at very high speed. It’s really not difficult to imagine this generating really superb, accessible, semantic code, and all the required input being “generate me a check answers page with X Y and Z fields on it”
What a gift.
And as the author notes in his Twitter thread, this thing doesn’t just build on technical knowledge. It builds on the design system which builds on years and years of work and research and experience; there is a lot of work that the check answers page rests on, in short, a lot of stuff from out here, and it’s expressed in here. We have language for it, which is why we can summon it.
 So I want to make a general observation here, which is that whenever you
go up a level of abstraction, your material, the stuff you work with,
looks a bit like the documentation for the last level of abstraction you
were at.
So I want to make a general observation here, which is that whenever you
go up a level of abstraction, your material, the stuff you work with,
looks a bit like the documentation for the last level of abstraction you
were at.
Today’s code is yesterday’s documentation. It tends to become more declarative as you go, look at SQL, look at the front end, Redux, Elm, modern dependency management, etc because we like to call things what they are, not by the bits they’re made of.
Obviously there is still a huge amount of technical work, including technical design work, to actually make those check answers pages and so on work. But this is not not progress.
So I think actually being pretty conservative if we predict this: everything over on the right of this diagram is going to continue to become a bit more declarative. Like Ruby, but better. Not into the low-code dead end. This way, you also get to keep the documentation! And no doubt this is the future of “low-code”.
I’m afraid that if we don’t embrace these abstractions, we are carving the back of the gargoyle that nobody is ever going to see. It’s true that abstraction hides control. There’s a reason why it’s legal to inline assembly in C, and why Python and Ruby packages and gems support native extensions. We like to keep a trapdoor back to a lower level.
And I’m going to say that over the course of the last year an increasingly conservative prediction is that everything over on the other side, the left hand side of the diagram, is also, for the first time, the very first time in history, going to become more declarative…
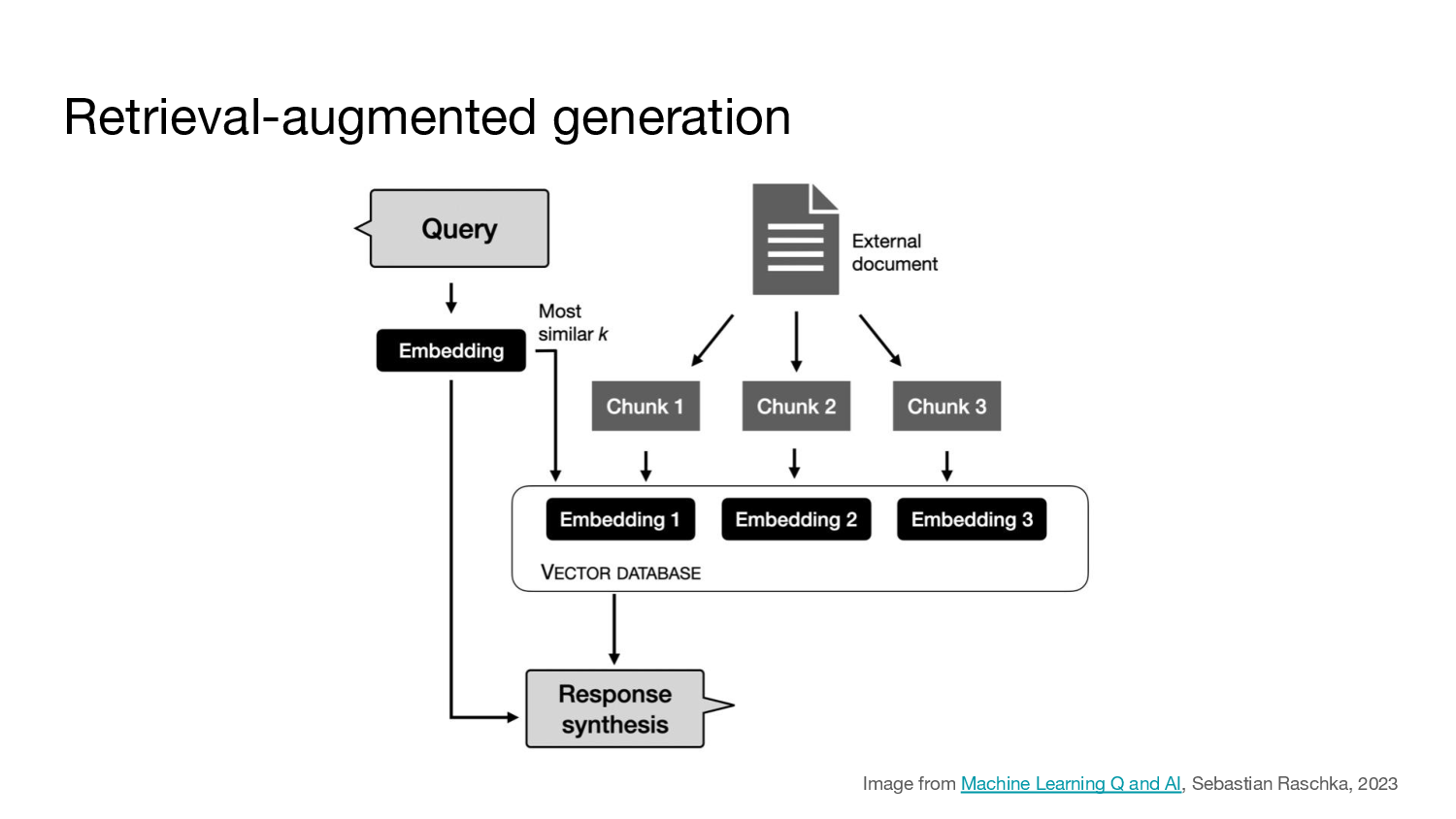
…thanks to this, or something like it.
This is called retrieval augmented generation. This is a process built upon something called “embeddings”, which are a byproduct of deep learning systems that work with natural language, like large language models. Apologies if you know what this is already. There’s a lot of good writing about this online if you’d like to know more, but suffice to say right now that amongst other things this gives us a way to do very effective and pretty fast similarity searches over large quantities of text (the “retrieval” part). And the traditional application is you take all the relevant gobbets of text and you put them in an LLM prompt, and then the LLM synthesises you a human-readable answer from the gobbets (the “generation” part).
And this is a powerful step, because a) this connects those slippery, unreliable LLMs to external sources of information, and b) you can arrange it so that the gobbets come with sources, so you can include checkable references in the output. And this keeps the human in the loop, just the same as we do when we create abstractions in code. This is is the same trapdoor.
You know you’re going up the ladder of abstraction when you feel like you want to hold on to the lower layer.
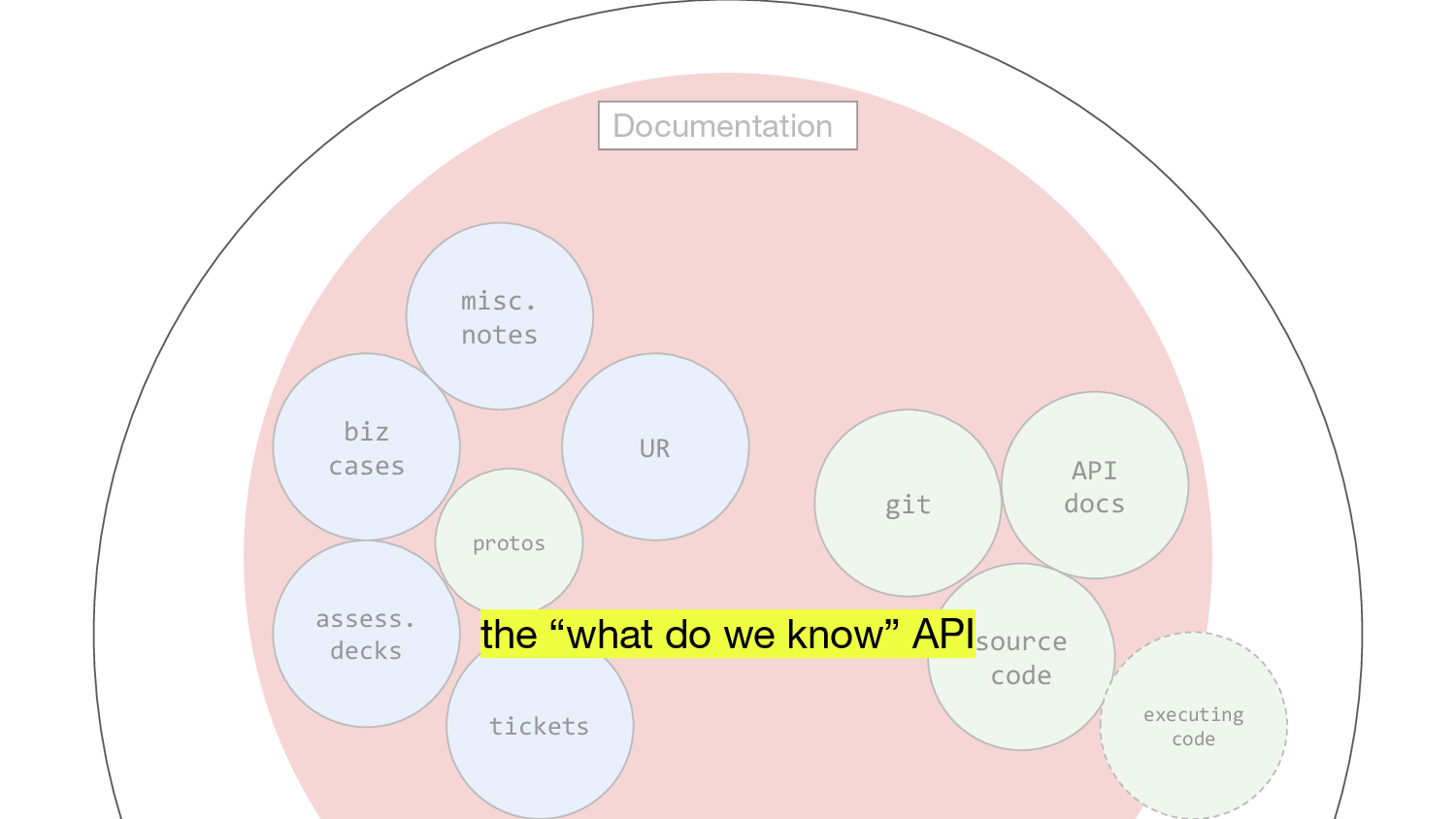
The thing which pulls us up, the reason why we’re willing to be the human in the loop for this, is that this thing can abstract over knowledge in the same way as a good API abstracts over logic. It’s an API for what we know. Take this heap of information and I shall declare what I want out of it. Just in time documentation, if you like. And this ought to be terrific. When what a team knows becomes something that’s really easy to look at and query and play with. This API for what we know builds an abstraction around all this—the executable, and the hitherto non-executable.
This is the reification of institutional memory. And of course the interface isn’t a document, it’s probably a chatbot.
In the essay where he talks about essential and accidental complexity, Fred Brooks says that there is “no silver bullet” to reduce essential complexity, but we can get close to it by doing things like iterative software development and using high-level languages. Brooks says (in 1986!) that there’s not much point trying to reduce accidental complexity any more because all the low hanging fruit has been plucked. In 1986!
But this change here, I think, Fred Brooks couldn’t possibly have foreseen. Because all this stuff here, these connections, they’re the “context” flavour of accidental complexity, which he naturally sees as distinct from the realm of automation. But it turns out that with this technology, we can reduce them. Specifically, we can reduce the amount of time we spend finding out what we know.
First of all this is going to be a superpower, and then it’s going to be table stakes.
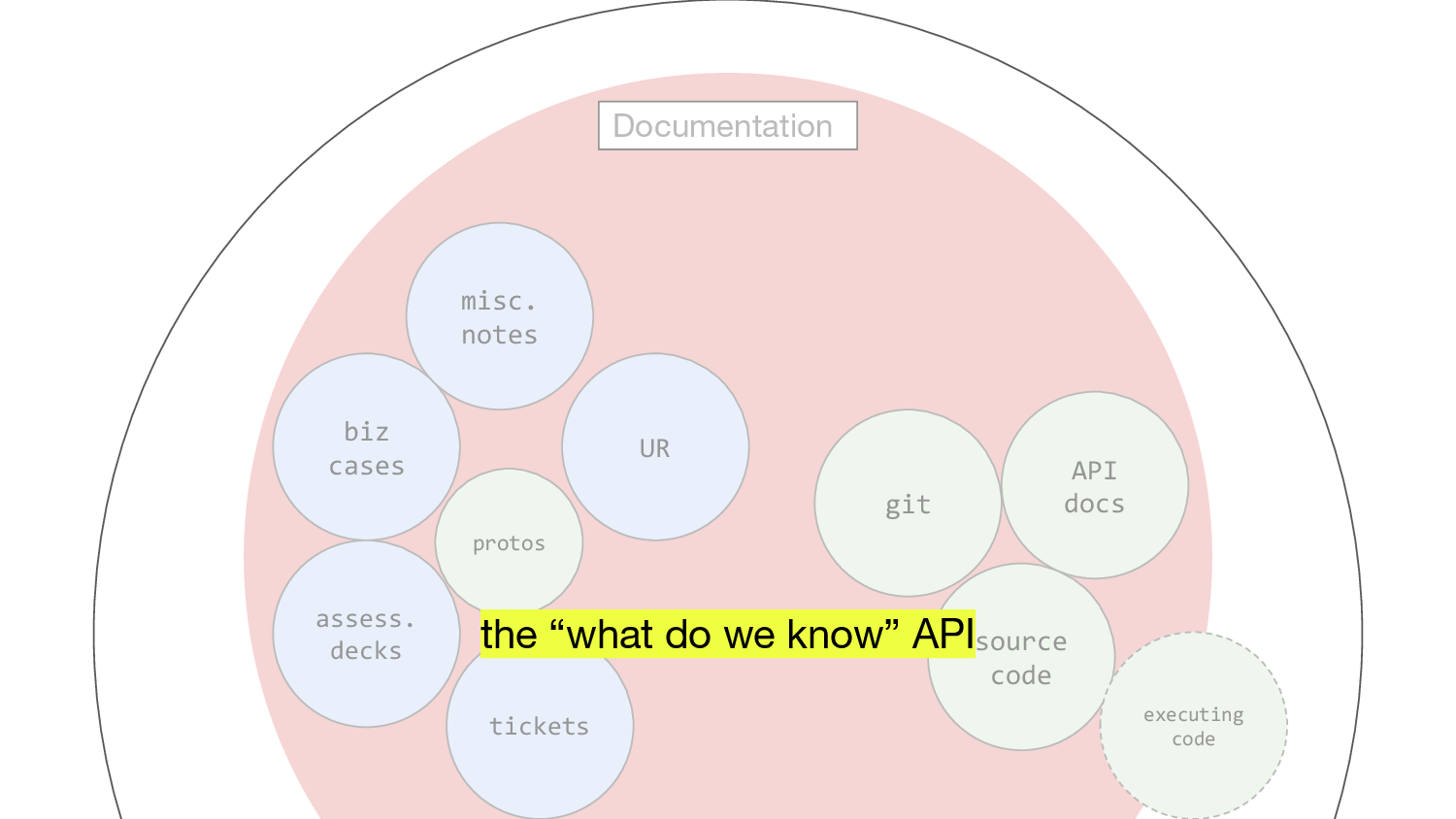
To be clear, if you can get all this stuff into the documentation writing machine—and I do believe you can, with technology we have today!—then you’re really cooking. Some cool things you can do with this are that for example maybe we’ll be able to identify things we’ve shipped but we haven’t thought about. Things for which there is no documentation or explanation or evidence. And stuff we’ve decided is a good idea but we actually haven’t done anything about, or are going against. And missing pieces. Prioritisation from a position of shared understanding!
That’s a lot to ask.
But it’s not, I think, too much to ask.
I’m waving my hand a bit here around technical implementation, because there is still going to be work to do there, but as team members we’re going to be empowered to engage a lot more actively with the stuff of design.

You will come with at least two objections: 1 the machine can’t know everything it will need to know to be useful, and 2. when there is all this information then the machine will become an editor, and that’s political, and the machine will be deciding how we think.
To the first point, yes there are a million micro decisions that we all make every day and we do not write that stuff down, to which I say, I think the future is weirder and kind of creepier than you think.
I think we will find ways to normalise giving Slack the right to offer you a chatbot over every public conversation in your organisation’s channels; teams calls etc will be recorded by default, or if that’s too intrusive there will be automated note taking of some sort, and UR teams that have all their notes and interviews in a system like this, and all these byproducts will no doubt contribute to this institutional-memory-as-a-service.
The realm of executability is no longer all over on the right. I don’t know what that means. But hell, here we are, so I just want to tie up the last thread here and finish on a slightly sci-fi note by way of answering the second objection, which to go back to those design histories and that code-like quality they have of drawing boundaries.
In a world where there is a large amount of information, and a small amount of writing which reflects what we want from that information, that’s analogous to the relationship between data and code respectively.
And in the realm of context it’s a concept that we don’t really have right now.
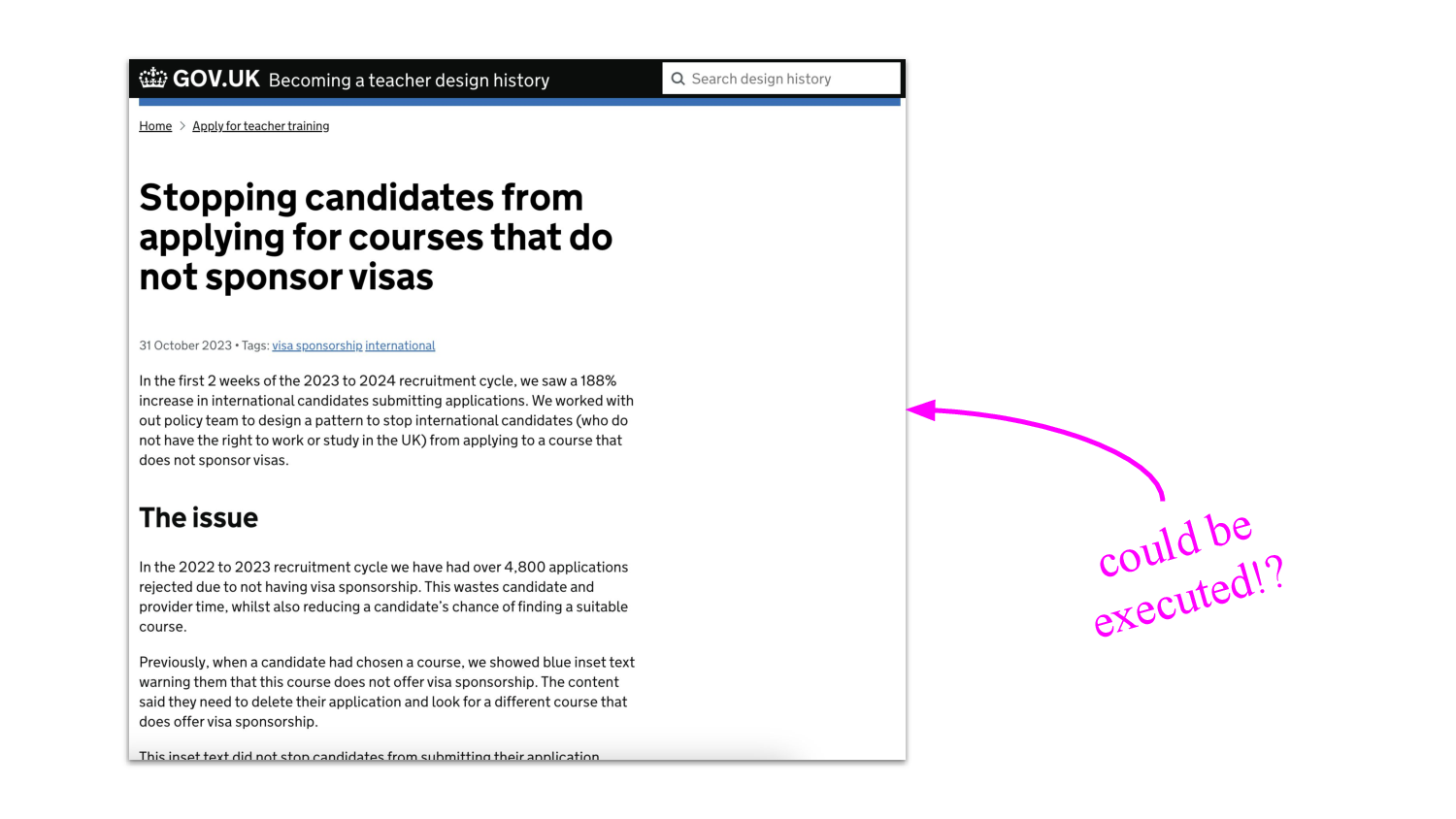
But if decision documents could be given special status — maybe this is no further away than a clever RAG prompt — if you like, a kind of supervising role, we could for instance receive answers which reflected our priorities, i.e. we would provide the bias.
Those documents would be things against which it’s possible to measure the success of the service or whatever in real life.
Executable decisions, distilling the desire or will of the team.
A newly executable artefact, which isn’t code.
Let’s call it… policy?
And we’ll look back in 20 years time and say can you believe we used to traffic all this stuff across all these boundaries, all these heads. Whereas since the mid 2020’s implementation and policy are have gradually become reconcilable, more explainable, and more consistently documented.
And over time, as the vocabulary grew, more and more of it tended to be carried out in the same language—English.
 Thank you very much.
Thank you very much.
#Documentation #Generative-Ai #Management #Programming #User-Centered-Design #Talks